Question # 4
You have an application running on Google Kubernetes Engine (GKE). The application is currently using a logging library and is outputting to standard output You need to export the logs to Cloud Logging, and you need the logs to include metadata about each request. You want to use the simplest method to accomplish this. What should you do?
Question # 5
Your data is stored in Cloud Storage buckets. Fellow developers have reported that data downloaded from Cloud Storage is resulting in slow API performance. You want to research the issue to provide details to the GCP support team. Which command should you run?
Question # 6
You are building a mobile application that will store hierarchical data structures in a database. The application will enable users working offline to sync changes when they are back online. A backend service will enrich the data in the database using a service account. The application is expected to be very popular and needs to scale seamlessly and securely. Which database and IAM role should you use?
Question # 7
You developed a JavaScript web application that needs to access Google Drive’s API and obtain permission from users to store files in their Google Drives. You need to select an authorization approach for your application. What should you do?
Question # 8
You have containerized a legacy application that stores its configuration on an NFS share. You need to deploy this application to Google Kubernetes Engine (GKE) and do not want the application serving traffic until after the configuration has been retrieved. What should you do?
Question # 9
You made a typo in a low-level Linux configuration file that prevents your Compute Engine instance from booting to a normal run level. You just created the Compute Engine instance today and have done no other maintenance on it, other than tweaking files. How should you correct this error?
Question # 10
You are using the Cloud Client Library to upload an image in your application to Cloud Storage. Users of the application report that occasionally the upload does not complete and the client library reports an HTTP 504 Gateway Timeout error. You want to make the application more resilient to errors. What changes to the application should you make?
Question # 11
You are deploying a microservices application to Google Kubernetes Engine (GKE). The application will receive daily updates. You expect to deploy a large number of distinct containers that will run on the Linux operating system (OS). You want to be alerted to any known OS vulnerabilities in the new containers. You want to follow Google-recommended best practices. What should you do?
Question # 12
You have decided to migrate your Compute Engine application to Google Kubernetes Engine. You need to build a container image and push it to Artifact Registry using Cloud Build. What should you do? (Choose two.)
A)
Run gcloud builds submit in the directory that contains the application source code.
B)
Run gcloud run deploy app-name --image gcr.io/$PROJECT_ID/app-name in the directory that contains the application source code.
C)
Run gcloud container images add-tag gcr.io/$PROJECT_ID/app-name gcr.io/$PROJECT_ID/app-name:latest in the directory that contains the application source code.
D)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:

E)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:

Question # 13
Your website is deployed on Compute Engine. Your marketing team wants to test conversion rates between 3
different website designs.
Which approach should you use?
Question # 14
You are designing a resource-sharing policy for applications used by different teams in a Google Kubernetes Engine cluster. You need to ensure that all applications can access the resources needed to run. What should you do? (Choose two.)
Question # 15
Your team is developing an application in Google Cloud that executes with user identities maintained by Cloud Identity. Each of your application’s users will have an associated Pub/Sub topic to which messages are published, and a Pub/Sub subscription where the same user will retrieve published messages. You need to ensure that only authorized users can publish and subscribe to their own specific Pub/Sub topic and subscription. What should you do?
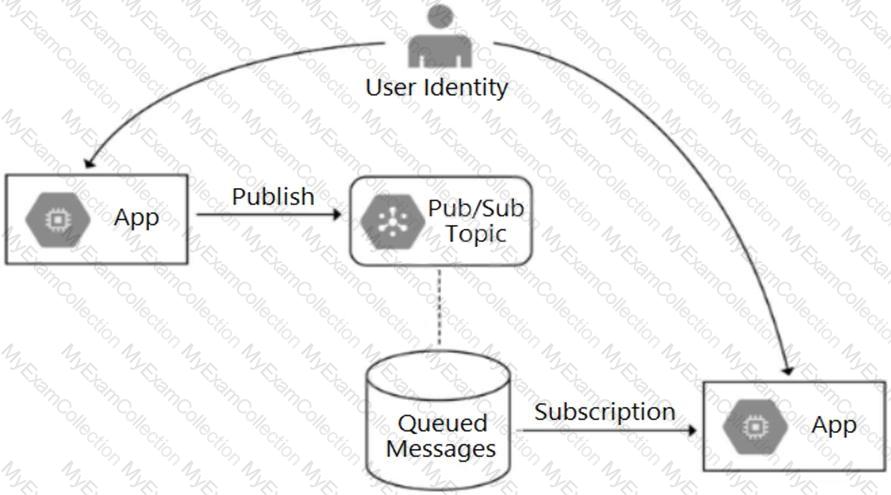
Question # 16
You are monitoring a web application that is written in Go and deployed in Google Kubernetes Engine. You notice an increase in CPU and memory utilization. You need to determine which source code is consuming the most CPU and memory resources. What should you do?
Question # 17
Your application performs well when tested locally, but it runs significantly slower when you deploy it to App Engine standard environment. You want to diagnose the problem. What should you do?
Question # 18
Your analytics system executes queries against a BigQuery dataset. The SQL query is executed in batch and passes the contents of a SQL file to the BigQuery CLI. Then it redirects the BigQuery CLI output to another process. However, you are getting a permission error from the BigQuery CLI when the queries are executed. You want to resolve the issue. What should you do?
Question # 19
You are creating and running containers across different projects in Google Cloud. The application you are developing needs to access Google Cloud services from within Google Kubernetes Engine (GKE).
What should you do?
Question # 20
You work on an application that relies on Cloud Spanner as its main datastore. New application features have occasionally caused performance regressions. You want to prevent performance issues by running an automated performance test with Cloud Build for each commit made. If multiple commits are made at the same time, the tests might run concurrently. What should you do?
Question # 21
You manage a microservices application on Google Kubernetes Engine (GKE) using Istio. You secure the communication channels between your microservices by implementing an Istio AuthorizationPolicy, a Kubernetes NetworkPolicy, and mTLS on your GKE cluster. You discover that HTTP requests between two Pods to specific URLs fail, while other requests to other URLs succeed. What is the cause of the connection issue?
Question # 22
For this question, refer to the HipLocal case study.
How should HipLocal redesign their architecture to ensure that the application scales to support a large increase in users?
Question # 23
In order for HipLocal to store application state and meet their stated business requirements, which database service should they migrate to?
Question # 24
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements.
Which configuration should they choose?
Question # 25
For this question, refer to the HipLocal case study.
Which Google Cloud product addresses HipLocal’s business requirements for service level indicators and objectives?
Question # 28
In order to meet their business requirements, how should HipLocal store their application state?
Question # 29
HipLocal is configuring their access controls.
Which firewall configuration should they implement?
Question # 30
HipLocal's.net-based auth service fails under intermittent load.
What should they do?
Question # 31
For this question refer to the HipLocal case study.
HipLocal wants to reduce the latency of their services for users in global locations. They have created read replicas of their database in locations where their users reside and configured their service to read traffic using those replicas. How should they further reduce latency for all database interactions with the least amount of effort?
Question # 32
For this question, refer to the HipLocal case study.
A recent security audit discovers that HipLocal’s database credentials for their Compute Engine-hosted MySQL databases are stored in plain text on persistent disks. HipLocal needs to reduce the risk of these credentials being stolen. What should they do?
Question # 33
For this question, refer to the HipLocal case study.
HipLocal's application uses Cloud Client Libraries to interact with Google Cloud. HipLocal needs to configure authentication and authorization in the Cloud Client Libraries to implement least privileged access for the application. What should they do?
Question # 34
HipLocal wants to reduce the number of on-call engineers and eliminate manual scaling.
Which two services should they choose? (Choose two.)
Question # 35
HipLocal's APIs are showing occasional failures, but they cannot find a pattern. They want to collect some
metrics to help them troubleshoot.
What should they do?
Question # 36
For this question, refer to the HipLocal case study.
How should HipLocal increase their API development speed while continuing to provide the QA team with a stable testing environment that meets feature requirements?
Question # 38
HipLocal has connected their Hadoop infrastructure to GCP using Cloud Interconnect in order to query data stored on persistent disks.
Which IP strategy should they use?
Question # 39
HipLocal’s data science team wants to analyze user reviews.
How should they prepare the data?
Question # 40
For this question, refer to the HipLocal case study.
HipLocal is expanding into new locations. They must capture additional data each time the application is launched in a new European country. This is causing delays in the development process due to constant schema changes and a lack of environments for conducting testing on the application changes. How should they resolve the issue while meeting the business requirements?

