Question # 4
Which of the following approaches can be used to view the notebook that was run to create an MLflow run?
Question # 5
A data scientist is using the following code block to tune hyperparameters for a machine learning model:

Which change can they make the above code block to improve the likelihood of a more accurate model?
Question # 6
A data scientist is using Spark SQL to import their data into a machine learning pipeline. Once the data is imported, the data scientist performs machine learning tasks using Spark ML.
Which of the following compute tools is best suited for this use case?
Question # 7
What is the name of the method that transforms categorical features into a series of binary indicator feature variables?
Question # 8
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
Question # 9
A machine learning engineer is converting a decision tree from sklearn to Spark ML. They notice that they are receiving different results despite all of their data and manually specified hyperparameter values being identical.
Which of the following describes a reason that the single-node sklearn decision tree and the Spark ML decision tree can differ?
Question # 10
A data scientist is wanting to explore the Spark DataFrame spark_df. The data scientist wants visual histograms displaying the distribution of numeric features to be included in the exploration.
Which of the following lines of code can the data scientist run to accomplish the task?
Question # 11
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
Question # 12
A data scientist has produced two models for a single machine learning problem. One of the models performs well when one of the features has a value of less than 5, and the other model performs well when the value of that feature is greater than or equal to 5. The data scientist decides to combine the two models into a single machine learning solution.
Which of the following terms is used to describe this combination of models?
Question # 13
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column price is greater than 0.
Which of the following code blocks will accomplish this task?
Question # 14
A machine learning engineer has created a Feature Table new_table using Feature Store Client fs. When creating the table, they specified a metadata description with key information about the Feature Table. They now want to retrieve that metadata programmatically.
Which of the following lines of code will return the metadata description?
Question # 15
A machine learning engineer wants to parallelize the inference of group-specific models using the Pandas Function API. They have developed theapply_modelfunction that will look up and load the correct model for each group, and they want to apply it to each group of DataFramedf.
They have written the following incomplete code block:

Which piece of code can be used to fill in the above blank to complete the task?
Question # 16
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A)

B)

C)
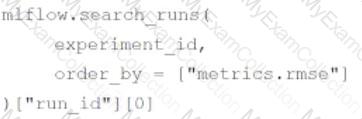
D)

Question # 17
A machine learning engineer would like to develop a linear regression model with Spark ML to predict the price of a hotel room. They are using the Spark DataFrametrain_dfto train the model.
The Spark DataFrametrain_dfhas the following schema:

The machine learning engineer shares the following code block:
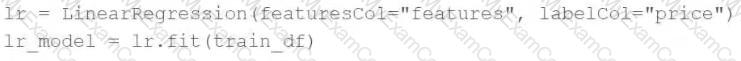
Which of the following changes does the machine learning engineer need to make to complete the task?
Question # 18
A data scientist uses 3-fold cross-validation when optimizing model hyperparameters for a regression problem. The following root-mean-squared-error values are calculated on each of the validation folds:
• 10.0
• 12.0
• 17.0
Which of the following values represents the overall cross-validation root-mean-squared error?
Question # 19
A machine learning engineer is trying to scale a machine learning pipelinepipelinethat contains multiple feature engineering stages and a modeling stage. As part of the cross-validation process, they are using the following code block:

A colleague suggests that the code block can be changed to speed up the tuning process by passing the model object to theestimatorparameter and then placing the updated cv object as the final stage of thepipelinein place of the original model.
Which of the following is a negative consequence of the approach suggested by the colleague?
Question # 20
A data scientist has developed a machine learning pipeline with a static input data set using Spark ML, but the pipeline is taking too long to process. They increase the number of workers in the cluster to get the pipeline to run more efficiently. They notice that the number of rows in the training set after reconfiguring the cluster is different from the number of rows in the training set prior to reconfiguring the cluster.
Which of the following approaches will guarantee a reproducible training and test set for each model?
Question # 21
Which of the following tools can be used to distribute large-scale feature engineering without the use of a UDF or pandas Function API for machine learning pipelines?
Question # 22
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
A)

B)

C)

D)


