Question # 5
Which SQL keyword can be used to convert a table from a long format to a wide format?
Question # 6
A new data engineering team team has been assigned to an ELT project. The new data engineering team will need full privileges on the table sales to fully manage the project.
Which command can be used to grant full permissions on the database to the new data engineering team?
Question # 7
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
Question # 8
Which of the following describes the relationship between Gold tables and Silver tables?
Question # 9
A data engineer is maintaining an ETL pipeline code with a GitHub repository linked to their Databricks account. The data engineer wants to deploy the ETL pipeline to production as a databricks workflow.
Which approach should the data engineer use?
Question # 10
A data engineer needs to create a table in Databricks using data from a CSV file at location /path/to/csv.
They run the following command:

Which of the following lines of code fills in the above blank to successfully complete the task?
Question # 11
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved.
Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
Question # 12
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to a data analytics dashboard for a retail use case. The job has a Databricks SQL query that returns the number of store-level records where sales is equal to zero. The data engineer wants their entire team to be notified via a messaging webhook whenever this value is greater than 0.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of stores with $0 in sales is greater than zero?
Question # 13
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:

If the data engineer only wants the query to process all of the available data in as many batches as required, which of the following lines of code should the data engineer use to fill in the blank?
Question # 14
A data engineer has been given a new record of data:
id STRING = ' a1 '
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
Question # 15
A data engineer needs to develop integration tests for an ETL process and deploy a version-controlled, packaged workflow into production using an external job scheduler.
Which tool should the data engineer use for this job?
Question # 16
A data engineer is attempting to drop a Spark SQL table my_table. The data engineer wants to delete all table metadata and data.
They run the following command:
DROP TABLE IF EXISTS my_table
While the object no longer appears when they run SHOW TABLES, the data files still exist.
Which of the following describes why the data files still exist and the metadata files were deleted?
Question # 17
A data engineer is using the OPTIMIZE command on a Delta table. What happens when OPTIMIZE is run twice on the same table with the same data?
Question # 18
In order for Structured Streaming to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing, which of the following two approaches is used by Spark to record the offset range of the data being processed in each trigger?
Question # 19
A Databricks single-task workflow fails at the last task due to an error in a notebook. The data engineer fixes the mistake in the notebook. What should the data engineer do to rerun the workflow?
Question # 20
What is the primary function of the Silver layer in the Databricks medallion architecture?
Question # 22
A data engineer has a Python notebook in Databricks, but they need to use SQL to accomplish a specific task within a cell. They still want all of the other cells to use Python without making any changes to those cells.
Which of the following describes how the data engineer can use SQL within a cell of their Python notebook?
Question # 23
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
Question # 24
A data engineer is migrating pipeline tasks to reduce operational toil. The workspace uses Unity Catalog and is in a region that supports serverless. The engineer wants Databricks to auto-select instance types, manage scaling, apply Photon, and handle runtime upgrades automatically for job runs.
How should the data engineer meet this requirement while adhering to Databricks constraints?
Question # 25
Which of the following describes a scenario in which a data team will want to utilize cluster pools?
Question # 26
Which of the following statements regarding the relationship between Silver tables and Bronze tables is always true?
Question # 27
A data engineer needs access to a table new_table, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is.
Which of the following approaches can be used to identify the owner of new_table?
Question # 28
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.

The code block used by the data engineer is below:
Which line of code should the data engineer use to fill in the blank if the data engineer only wants the query to execute a micro-batch to process data every 5 seconds?
Question # 30
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
Question # 31
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which of the following locations can the data engineer review their permissions on the table?
Question # 32
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company ' s custom-defined network in the cloud. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
Question # 33
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
Question # 34
A data engineer wants to create a relational object by pulling data from two tables. The relational object does not need to be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data.
Which of the following relational objects should the data engineer create?
Question # 35
A data analyst has a series of queries in a SQL program. The data analyst wants this program to run every day. They only want the final query in the program to run on Sundays. They ask for help from the data engineering team to complete this task.
Which of the following approaches could be used by the data engineering team to complete this task?
Question # 36
Which of the following tools is used by Auto Loader process data incrementally?
Question # 37
A data engineer streams customer orders into a Kafka topic (orders_topic) and is currently writing the ingestion script of a DLT pipeline. The data engineer needs to ingest the data from Kafka brokers to DLT using Databricks
What is the correct code for ingesting the data?
A)

B)
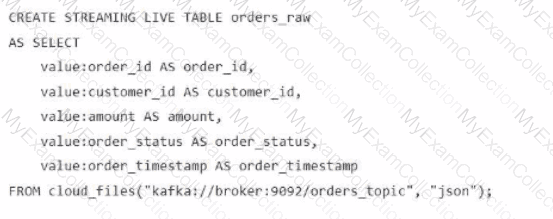
C)

D)

Question # 38
A data engineer needs to process SQL queries on a large dataset with fluctuating workloads. The workload requires automatic scaling based on the volume of queries, without the need to manage or provision infrastructure. The solution should be cost-efficient and charge only for the compute resources used during query execution.
Which compute option should the data engineer use?
Question # 39
A data engineer is reviewing the documentation on audit logs in Databricks for compliance purposes and needs to understand the format in which audit logs output events.
How are events formatted in Databricks audit logs?
Question # 40
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Question # 42
A data engineer wants to create an external table in Databricks that references data stored in an Azure Data Lake Storage (ADLS) location. The goal is to enable Databricks to access and query this external data without moving it into Databricks-managed storage.
Which step should the data engineer take to successfully create the external table?
Question # 44
A data engineer is working in a Python notebook on Databricks to process data, but notices that the output is not as expected. The data engineer wants to investigate the issue by stepping through the code and checking the values of certain variables during execution.
Which tool should the data engineer use to inspect the code execution and variables in real-time?
Question # 45
Which of the following is a benefit of the Databricks Lakehouse Platform embracing open source technologies?
Question # 46
A data engineer needs to provide access to a group named manufacturing-team. The team needs privileges to create tables in the quality schema.
Which set of SQL commands will grant a group named manufacturing-team to create tables in a schema named production with the parent catalog named manufacturing with the least privileges?
A)

B)

C)

D)

Question # 47
Which of the following benefits is provided by the array functions from Spark SQL?
Question # 49
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command:

A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
Question # 50
A data engineering project involves processing large batches of data on a daily schedule using ETL. The jobs are resource-intensive and vary in size, requiring a scalable, cost-efficient compute solution that can automatically scale based on the workload.
Which compute approach will satisfy the needs described?
Question # 51
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_a. count(*) as count_b.count(col1) as count_c from random_values col1
0
1
2
NULL -
2
3
Question # 52
A data engineer needs to ingest from both streaming and batch sources for a firm that relies on highly accurate data. Occasionally, some of the data picked up by the sensors that provide a streaming input are outside the expected parameters. If this occurs, the data must be dropped, but the stream should not fail.
Which feature of Delta Live Tables meets this requirement?

