Question # 4
Which service or tool is a Command Line Interface (CLI) client used for connecting to Snowflake to execute SQL queries?
Question # 6
How can performance be optimized for a query that returns a small amount of data from a very large base table?
Question # 7
Which of the following conditions must be met in order to return results from the results cache? (Select TWO).
Question # 9
What versions of Snowflake should be used to manage compliance with Personal Identifiable Information (PII) requirements? (Choose two.)
Question # 10
Which Snowflake table stores file-level metadata about unstructured data files in a stage, including size, last-modified timestamp, and Snowflake file URL?
Question # 11
If 3 size Small virtual warehouse is made up of two servers, how many servers make up a Large warehouse?

Question # 12
A table gets updated throughout the day. A user wants to automate the process of table changes by capturing only the changed rows every 20 minutes and applying transformations without manual intervention. How can this be accomplished?
Question # 13
During periods of warehouse contention which parameter controls the maximum length of time a warehouse will hold a query for processing?
Question # 14
Why does Snowflake recommend file sizes of 100-250 MB compressed when loading data?
Question # 15
What privileges are required to allow role RL_CUST_WH to start warehouse CUST_WH?
Question # 16
What is the minimum Snowflake edition required to use Dynamic Data Masking?
Question # 17
Which Snowflake SQL statement would be used to determine which users and roles have access to a role called MY_ROLE?
Question # 18
A user has unloaded data from a Snowflake table to an external stage.
Which command can be used to verify if data has been uploaded to the external stage named my_stage?
Question # 19
The Snowflake Search Optimization Services supports improved performance of which kind of query?
Question # 20
How does Snowflake define i1s approach to Discretionary Access Control (DAC)?
Question # 21
When loading data into Snowflake via Snowpipe what is the compressed file size recommendation?
Question # 22
What is the SNOWFLAKE.ACCOUNT_USAGE view that contains information about which objects were read by queries within the last 365 days (1 year)?
Question # 23
Which SQL commands, when committed, will consume a stream and advance the stream offset? (Choose two.)
Question # 24
Which file formats are supported for unloading data from Snowflake? (Choose two.)
Question # 27
Which snowflake objects will incur both storage and cloud compute charges? (Select TWO)
Question # 28
A user created a new worksheet within the Snowsight Ul and wants to share this with teammates
How can this worksheet be shared?
Question # 29
Which of the following objects are contained within a schema? (Choose two.)
Question # 31
Which of the following features, associated with Continuous Data Protection (CDP), require additional Snowflake-provided data storage? (Choose two.)
Question # 32
True or False: Snowpipe via REST API can only reference External Stages as source.
Question # 34
Which Snowflake function will interpret an input string as a JSON document, and produce a VARIANT value?
Question # 35
Which services does the Snowflake Cloud Services layer manage? (Choose two.)
Question # 36
A marketing co-worker has requested the ability to change a warehouse size on their medium virtual warehouse called mktg__WH.
Which of the following statements will accommodate this request?
Question # 37
Which services does the Snowflake Cloud Services layer manage? (Select TWO).
Question # 39
In the Snowflake access control model, which entity owns an object by default?
Question # 40
Which data types can be used in Snowflake to store semi-structured data? (Select TWO)
Question # 42
Which of the following statements describe features of Snowflake data caching? (Choose two.)
Question # 43
Which tasks are performed in the Snowflake Cloud Services layer? (Choose two.)
Question # 44
Which Snowflake layer is always leveraged when accessing a query from the result cache?
Question # 45
How can a row access policy be applied to a table or a view? (Choose two.)
Question # 46
A user is preparing to load data from an external stage
Which practice will provide the MOST efficient loading performance?
Question # 47
What impacts the credit consumption of maintaining a materialized view? (Choose two.)
Question # 49
Which Snowflake architectural layer is responsible for a query execution plan?
Question # 51
What is the minimum Snowflake Edition that supports secure storage of Protected Health Information (PHI) data?
Question # 52
The Snowflake Cloud Data Platform is described as having which of the following architectures?
Question # 53
What are the responsibilities of Snowflake ' s Cloud Service layer? (Choose three.)
Question # 56
What is the maximum Time Travel retention period for a temporary Snowflake table?
Question # 58
A table needs to be loaded. The input data is in JSON format and is a concatenation of multiple JSON documents. The file size is 3 GB. A warehouse size small is being used. The following COPY INTO command was executed:
COPY INTO SAMPLE FROM @~/SAMPLE.JSON (TYPE=JSON)
The load failed with this error:
Max LOB size (16777216) exceeded, actual size of parsed column is 17894470.
How can this issue be resolved?
Question # 59
What is the MINIMUM edition of Snowflake that is required to use a SCIM security integration?
Question # 60
When publishing a Snowflake Data Marketplace listing into a remote region what should be taken into consideration? (Choose two.)
Question # 61
What are the correct parameters for time travel and fail-safe in the Snowflake Enterprise Edition?
Question # 62
Assume there is a table consisting of five micro-partitions with values ranging from A to Z.
Which diagram indicates a well-clustered table?
Question # 63
What are key characteristics of virtual warehouses in Snowflake? (Select TWO).
Question # 65
A single user of a virtual warehouse has set the warehouse to auto-resume and auto-suspend after 10 minutes. The warehouse is currently suspended and the user performs the following actions:
1. Runs a query that takes 3 minutes to complete
2. Leaves for 15 minutes
3. Returns and runs a query that takes 10 seconds to complete
4. Manually suspends the warehouse as soon as the last query was completed
When the user returns, how much billable compute time will have been consumed?
Question # 66
What happens to historical data when the retention period for an object ends?
Question # 67
Which of the following are best practices for loading data into Snowflake? (Choose three.)
Question # 68
Which statements are true concerning Snowflake ' s underlying cloud infrastructure? (Select THREE),
Question # 69
What is the maximum total Continuous Data Protection (CDP) charges incurred for a temporary table?
Question # 72
For the ALLOWED VALUES tag property, what is the MAXIMUM number of possible string values for a single tag?
Question # 73
Network policies can be applied to which of the following Snowflake objects? (Choose two.)
Question # 74
Which command is used to unload files from an internal or external stage to a local file system?
Question # 76
How often are the Account and Table master keys automatically rotated by Snowflake?
Question # 80
If queries start to queue in a multi-cluster virtual warehouse, an additional compute cluster starts immediately under what setting?
Question # 82
A Snowflake user executed a query and received the results. Another user executed the same query 4 hours later. The data had not changed.
What will occur?
Question # 83
If file format options are specified in multiple locations, the load operation selects which option FIRST to apply in order of precedence?
Question # 84
Which file format will keep floating-point numbers from being truncated when data is unloaded?
Question # 85
Which SQL command can be used to see the CREATE definition of a masking policy?
Question # 88
Which database objects can be shared with the Snowflake secure data sharing feature? (Choose two.)
Question # 90
A data provider wants to share data with a consumer who does not have a Snowflake account. The provider creates a reader account for the consumer following these steps:
1. Created a user called " CONSUMER "
2. Created a database to hold the share and an extra-small warehouse to query the data
3. Granted the role PUBLIC the following privileges: Usage on the warehouse, database, and schema, and SELECT on all the objects in the share
Based on this configuration what is true of the reader account?
Question # 91
How can a data provider ensure that a data consumer is going to have access to the required objects?
Question # 92
What privilege should a user be granted to change permissions for new objects in a managed access schema?
Question # 93
A tabular User-Defined Function (UDF) is defined by specifying a return clause that contains which keyword?
Question # 94
What column type does a Kafka connector store formatted information in a single column?
Question # 95
Which parameter can be used to instruct a COPY command to verify data files instead of loading them into a specified table?
Question # 96
In which Snowflake layer does Snowflake reorganize data into its internal optimized, compressed, columnar format?
Question # 98
What is the recommended compressed file size range for continuous data loads using Snowpipe?
Question # 99
How do Snowflake data providers share data that resides in different databases?
Question # 102
Which Snowflake object helps evaluate virtual warehouse performance impacted by query queuing?
Question # 104
How can a Snowflake user access a JSON object, given the following table? (Select TWO).
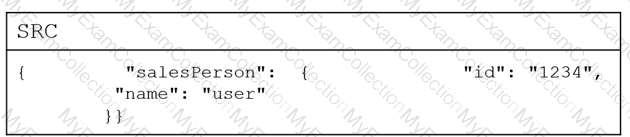
Question # 105
Which stream type can be used for tracking the records in external tables?
Question # 107
How long can a data consumer who has a pre-signed URL access data files using Snowflake?
Question # 108
Which feature is integrated to support Multi-Factor Authentication (MFA) at Snowflake?
Question # 109
A Snowflake user has two tables that contain numeric values and is trying to find out which values are present in both tables. Which set operator should be used?
Question # 110
When would Snowsight automatically detect if a target account is in a different region and enable cross-cloud auto-fulfillment?
Question # 111
What computer language can be selected when creating User-Defined Functions (UDFs) using the Snowpark API?
Question # 112
Which Snowflake URL type allows users or applications to download or access files directly from Snowflake stage without authentication?
Question # 113
A Snowflake user has been granted the create data EXCHANGE listing privilege with their role.
Which tasks can this user now perform on the Data Exchange? (Select TWO).
Question # 114
What is the recommended way to change the existing file format type in my format from CSV to JSON?
Question # 115
Which Snowflake objects can be shared with other Snowflake accounts? (Choose three.)
Question # 117
Which feature allows a user the ability to control the organization of data in a micro-partition?
Question # 118
Which operations are handled in the Cloud Services layer of Snowflake? (Select TWO).
Question # 119
A user needs to create a materialized view in the schema MYDB.MYSCHEMA. Which statements will provide this access?
Question # 120
Which native data types are used for storing semi-structured data in Snowflake? (Select TWO)
Question # 123
Which kind of Snowflake table stores file-level metadata for each file in a stage?
Question # 125
What is the purpose of using the OBJECT_CONSTRUCT function with me COPY INTO command?
Question # 127
Which of the following Snowflake features provide continuous data protection automatically? (Select TWO).
Question # 131
What SQL command would be used to view all roles that were granted to user.1?
Question # 132
Which of the following objects can be shared through secure data sharing?
Question # 133
True or False: Reader Accounts are able to extract data from shared data objects for use outside of Snowflake.
Question # 134
Which account__usage views are used to evaluate the details of dynamic data masking? (Select TWO)
Question # 135
Which of the following Snowflake objects can be shared using a secure share? (Select TWO).
Question # 136
Which data types does Snowflake support when querying semi-structured data? (Select TWO)
Question # 137
Which semi-structured file formats are supported when unloading data from a table? (Select TWO).
Question # 138
Which of the following describes how multiple Snowflake accounts in a single organization relate to various cloud providers?
Question # 139
A user has 10 files in a stage containing new customer data. The ingest operation completes with no errors, using the following command:
COPY INTO my__table FROM @my__stage;
The next day the user adds 10 files to the stage so that now the stage contains a mixture of new customer data and updates to the previous data. The user did not remove the 10 original files.
If the user runs the same copy into command what will happen?
Question # 140
A user needs to create a materialized view in the schema MYDB.MYSCHEMA.
Which statements will provide this access?
Question # 141
A user is loading JSON documents composed of a huge array containing multiple records into Snowflake. The user enables the strip__outer_array file format option
What does the STRIP_OUTER_ARRAY file format do?
Question # 142
Where would a Snowflake user find information about query activity from 90 days ago?
Question # 144
A company ' s security audit requires generating a report listing all Snowflake logins (e.g.. date and user) within the last 90 days. Which of the following statements will return the required information?
Question # 145
What are the default Time Travel and Fail-safe retention periods for transient tables?
Question # 147
What feature can be used to reorganize a very large table on one or more columns?
Question # 148
What Snowflake features allow virtual warehouses to handle high concurrency workloads? (Select TWO)
Question # 150
True or False: Loading data into Snowflake requires that source data files be no larger than 16MB.
Question # 151
Which Snowflake technique can be used to improve the performance of a query?
Question # 152
In which scenarios would a user have to pay Cloud Services costs? (Select TWO).
Question # 153
A company strongly encourages all Snowflake users to self-enroll in Snowflake ' s default Multi-Factor Authentication (MFA) service to provide increased login security for users connecting to Snowflake.
Which application will the Snowflake users need to install on their devices in order to connect with MFA?
Question # 159
Which is the MINIMUM required Snowflake edition that a user must have if they want to use AWS/Azure Privatelink or Google Cloud Private Service Connect?
Question # 160
A user unloaded a Snowflake table called mytable to an internal stage called mystage.
Which command can be used to view the list of files that has been uploaded to the staged?
Question # 161
A virtual warehouse ' s auto-suspend and auto-resume settings apply to which of the following?
Question # 162
A developer is granted ownership of a table that has a masking policy. The developer ' s role is not able to see the masked data. Will the developer be able to modify the table to read the masked data?
Question # 163
Which of the following compute resources or features are managed by Snowflake? (Select TWO).
Question # 164
When unloading to a stage, which of the following is a recommended practice or approach?
Question # 169
What is the default File Format used in the COPY command if one is not specified?
Question # 170
What transformations are supported in a CREATE PIPE ... AS COPY ... FROM (....) statement? (Select TWO.)
Question # 171
What happens when a cloned table is replicated to a secondary database? (Select TWO)
Question # 172
When reviewing a query profile, what is a symptom that a query is too large to fit into the memory?
Question # 174
Which command should be used to load data from a file, located in an external stage, into a table in Snowflake?
Question # 176
A user has an application that writes a new Tile to a cloud storage location every 5 minutes.
What would be the MOST efficient way to get the files into Snowflake?
Question # 177
What are two ways to create and manage Data Shares in Snowflake? (Choose two.)
Question # 179
If a virtual warehouse runs for 61 seconds, shut down, and then restart and runs for 30 seconds, for how many seconds is it billed?
Question # 180
What is the default value in the Snowflake Web Interface (Ul) for auto suspending a Virtual Warehouse?
Question # 181
Which command should be used to unload all the rows from a table into one or more files in a named stage?
Question # 182
Which function is used to convert rows in a relational table to a single VARIANT column?
Question # 183
What is it called when a customer managed key is combined with a Snowflake managed key to create a composite key for encryption?
Question # 184
What is the MINIMUM permission needed to access a file URL from an external stage?
Question # 185
What criteria does Snowflake use to determine the current role when initiating a session? (Select TWO).
Question # 186
What SnowFlake database object is derived from a query specification, stored for later use, and can speed up expensive aggregation on large data sets?
Question # 189
By default, how long is the standard retention period for Time Travel across all Snowflake accounts?
Question # 190
Which view can be used to determine if a table has frequent row updates or deletes?
Question # 192
How does a Snowflake stored procedure compare to a User-Defined Function (UDF)?
Question # 193
What is the MAXIMUM number of clusters that can be provisioned with a multi-cluster virtual warehouse?
Question # 194
When floating-point number columns are unloaded to CSV or JSON files, Snowflake truncates the values to approximately what?
Question # 196
A user has semi-structured data to load into Snowflake but is not sure what types of operations will need to be performed on the data. Based on this situation, what type of column does Snowflake recommend be used?
Question # 199
A Snowflake user wants to temporarily bypass a network policy by configuring the user object property MINS_TO_BYPASS_NETWORK_POLICY.
What should they do?
Question # 200
There are two Snowflake accounts in the same cloud provider region: one is production and the other is non-production. How can data be easily transferred from the production account to the non-production account?
Question # 201
When referring to User-Defined Function (UDF) names in Snowflake, what does the term overloading mean?
Question # 202
Which data formats are supported by Snowflake when unloading semi-structured data? (Select TWO).
Question # 203
A user wants to add additional privileges to the system-defined roles for their virtual warehouse. How does Snowflake recommend they accomplish this?
Question # 204
Regardless of which notation is used, what are considerations for writing the column name and element names when traversing semi-structured data?
Question # 205
What is the only supported character set for loading and unloading data from all supported file formats?
Question # 206
Which Snowflake mechanism is used to limit the number of micro-partitions scanned by a query?
Question # 207
The effects of query pruning can be observed by evaluating which statistics? (Select TWO).
Question # 208
A Snowflake user is writing a User-Defined Function (UDF) that includes some unqualified object names.
How will those object names be resolved during execution?
Question # 209
Which role has the ability to create a share from a shared database by default?
Question # 212
By default, which role has access to the SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER function?
Question # 213
Which common query problems are identified by the Query Profile? (Select TWO.)
Question # 215
For Directory tables, what stage allows for automatic refreshing of metadata?
Question # 216
How does a Snowflake user extract the URL of a directory table on an external stage for further transformation?
Question # 217
What are valid sub-clauses to the OVER clause for a window function? (Select TWO).
Question # 218
What should be used when creating a CSV file format where the columns are wrapped by single quotes or double quotes?
Question # 220
Which command can be used to list all the file formats for which a user has access privileges?
Question # 221
What is the Fail-safe period for a transient table in the Snowflake Enterprise edition and higher?
Question # 224
What are the benefits of the replication feature in Snowflake? (Select TWO).
Question # 225
What will happen if a Snowflake user increases the size of a suspended virtual warehouse?
Question # 226
Which Snowflake role can manage any object grant globally, including modifying and revoking grants?
Question # 227
While working with unstructured data, which file function generates a Snowflake-hosted file URL to a staged file using the stage name and relative file path as inputs?
Question # 229
Which file function generates a SnowFlake-hosted URL that must be authenticated when used?
Question # 231
What happens when a network policy includes values that appear in both the allowed and blocked IP address list?
Question # 233
User1, who has the SYSADMIN role, executed a query on Snowsight. User2, who is in the same Snowflake account, wants to view the result set of the query executed by User1 using the Snowsight query history.
What will happen if User2 tries to access the query history?
Question # 234
The VALIDATE table function has which parameter as an input argument for a Snowflake user?
Question # 236
While clustering a table, columns with which data types can be used as clustering keys? (Select TWO).
Question # 237
A tag object has been assigned to a table (TABLE_A) in a schema within a Snowflake database.
Which CREATE object statement will automatically assign the TABLE_A tag to a target object?
Question # 239
What metadata does Snowflake store for rows in micro-partitions? (Select TWO).
Question # 240
A column named " Data " contains VARIANT data and stores values as follows:
How will Snowflake extract the employee ' s name from the column data?
Question # 244
What happens to the objects in a reader account when the DROP MANAGED ACCOUNT command is executed?
Question # 245
Which Snowflake feature provides increased login security for users connecting to Snowflake that is powered by Duo Security service?
Question # 248
What objects in Snowflake are supported by Dynamic Data Masking? (Select TWO). '
Question # 249
Which statistics are displayed in a Query Profile that indicate that intermediate results do not fit in memory? (Select TWO).
Question # 250
What is the purpose of the STRIP NULL_VALUES file format option when loading semi-structured data files into Snowflake?
Question # 251
Which solution improves the performance of point lookup queries that return a small number of rows from large tables using highly selective filters?
Question # 252
A permanent table and temporary table have the same name, TBL1, in a schema.
What will happen if a user executes select * from TBL1 ;?
Question # 255
When enabling access to unstructured data, which URL permits temporary access to a staged file without the need to grant privileges to the stage or to issue access tokens?
Question # 256
When using the ALLOW CLIENT_MFA_CACHING parameter, how long is a cached Multi-Factor Authentication (MFA) token valid for?
Question # 257
What happens when a Snowflake user changes the data retention period at the schema level?
Question # 258
Which Snowflake table objects can be shared with other accounts? (Select TWO).
Question # 259
Which parameter can be set at the account level to set the minimum number of days for which Snowflake retains historical data in Time Travel?
Question # 261
Which Snowflake data types can be used to build nested hierarchical data? (Select TWO)
Question # 263
Which metadata table will store the storage utilization information even for dropped tables?
Question # 269
Use of which feature or setting consumes Snowflake credits, but generates no storage costs?
Question # 270
When a replication schedule is set, how does Snowflake manage refreshes for failover groups?
Question # 271
What Snowflake feature provides a data hub for secure data collaboration, with a selected group of invited members?
Question # 273
A Snowflake account has activated federated authentication.
What will occur when a user with a password that was defined by Snowflake attempts to log in to Snowflake?
Question # 274
Which privilege must be granted by one role to another role, and cannot be revoked?
Question # 275
When working with a managed access schema, who has the OWNERSHIP privilege of any tables added to the schema?
Question # 276
A user wants to access files stored in a stage without authenticating into Snowflake. Which type of URL should be used?
Question # 277
What feature of Snowflake Continuous Data Protection can be used for maintenance of historical data?
Question # 279
How should clustering be used to optimize the performance of queries that run on a very large table?
Question # 280
Which Snowflake feature allows a user to track sensitive data for compliance, discovery, protection, and resource usage?
Question # 282
Which ACCOUNT_USAGE schema database role provides visibility into policy-related information?
Question # 283
Which statements describe benefits of Snowflake ' s separation of compute and storage? (Select TWO).
Question # 284
How can a Snowflake administrator determine which user has accessed a database object that contains sensitive information?
Question # 285
How can a Snowflake user validate data that is unloaded using the COPY INTO < location > command?
Question # 286
What is the FASTEST way to load a specific, staged, discrete set of files using the COPY INTO < table > command?

