Question # 4
When using the Operations Dashboard, which of the following is supported for encryption of data at rest?
A.
AES128
B.
Portworx
C.
base64
D.
NFS
Full Access
Answer:
B
Explanation:
The Operations Dashboard in IBM Cloud Pak for Integration (CP4I) v2021.2 is used for monitoring and managing integration components. When securing data at rest, the supported encryption method in CP4I includes Portworx, which provides enterprise-grade storage and encryption solutions.
Portworx is a Kubernetes-native storage solution that supports encryption of data at rest.
It enables persistent storage for OpenShift workloads, including Cloud Pak for Integration components.
Portworx provides AES-256 encryption, ensuring that data at rest remains secure.
It allows for role-based access control (RBAC) and Key Management System (KMS) integration for secure key handling.
Why Option B (Portworx) is Correct:
A. AES128 → Incorrect
While AES encryption is used for data protection, AES128 is not explicitly mentioned as the standard for Operations Dashboard storage encryption.
AES-256 is the preferred encryption method when using Portworx or IBM-provided storage solutions.
C. base64 → Incorrect
Base64 is an encoding scheme, not an encryption method.
It does not provide security for data at rest, as base64-encoded data can be easily decoded.
D. NFS → Incorrect
Network File System (NFS) does not inherently provide encryption for data at rest.
NFS can be used for storage, but additional encryption mechanisms are needed for securing data at rest.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration Security Best Practices
Portworx Data Encryption Documentation
IBM Cloud Pak for Integration Storage Considerations
Red Hat OpenShift and Portworx Integration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
https://www.ibm.com/docs/en/cloud-paks/cp-integration/2020.3?topic=configuration-installation
Question # 5
In the Cloud Pak for Integration platform, which two roles can be used to connect to an LDAP Directory?
A.
Cloud Pak administrator
B.
Cluster administrator
C.
Cluster manager
D.
Cloud Pak root
E.
Cloud Pak user
Full Access
Answer:
A
Explanation:
In IBM Cloud Pak for Integration (CP4I), Lightweight Directory Access Protocol (LDAP) integration allows centralized authentication and user management. To configure LDAP and establish a connection, users must have sufficient privileges within the Cloud Pak environment.
The two roles that can connect and configure LDAP are:
Cloud Pak administrator (A) – ✅ Correct
This role has full administrative access to Cloud Pak services, including configuring authentication and integrating with external directories like LDAP.
A Cloud Pak administrator can define identity providers and manage user access settings.
Cluster administrator (B) – ✅ Correct
The Cluster administrator role has control over the OpenShift cluster, including managing security settings, authentication providers, and infrastructure configurations.
Since LDAP integration requires changes at the cluster level, this role is also capable of configuring LDAP connections.
C. Cluster manager (Incorrect)
There is no predefined "Cluster manager" role in Cloud Pak for Integration that specifically handles LDAP integration.
D. Cloud Pak root (Incorrect)
No official "Cloud Pak root" role exists. Root-level access typically refers to system-level privileges but is not a designated role in Cloud Pak.
D. Cloud Pak user (Incorrect)
Cloud Pak users have limited permissions and can only access assigned services; they cannot configure LDAP or authentication settings.
Analysis of Incorrect Options:
IBM Cloud Pak for Integration - Managing Authentication and LDAP
OpenShift Cluster Administrator Role and Access Control
IBM Cloud Pak - Configuring External Identity Providers
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 6
Which two OpenShift project names can be used for installing the Cloud Pak for Integration operator?
A.
openshift-infra
B.
openshift
C.
default
D.
cp4i
E.
openshift-cp4i
Full Access
Answer:
D, E
Explanation:
When installing the Cloud Pak for Integration (CP4I) operator on OpenShift, administrators must select an appropriate OpenShift project (namespace).
IBM recommends using dedicated namespaces for CP4I installation to ensure proper isolation and resource management. The two commonly used namespaces are:
cp4i → A custom namespace that administrators often create specifically for CP4I components.
openshift-cp4i → A namespace prefixed with openshift-, often used in managed environments or to align with OpenShift conventions.
Both of these namespaces are valid for CP4I installation.
A. openshift-infra → ⌠Incorrect
The openshift-infra namespace is reserved for internal OpenShift infrastructure components (e.g., monitoring and networking).
It is not intended for application or operator installations.
B. openshift → ⌠Incorrect
The openshift namespace is a protected namespace used by OpenShift’s core services.
Installing CP4I in this namespace can cause conflicts and is not recommended.
C. default → ⌠Incorrect
The default namespace is a generic OpenShift project that lacks the necessary role-based access control (RBAC) configurations for CP4I.
Using this namespace can lead to security and permission issues.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration Installation Guide
OpenShift Namespace Best Practices
IBM Cloud Pak for Integration Operator Deployment
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
https://www.ibm.com/docs/en/cloud-paks/cp-integration/2021.2?topic=installing-operators
Question # 7
Which two storage types are required before installing Automation Assets?
A.
Asset data storage - a File RWX volume
B.
Asset metadata storage - a Block RWO volume
C.
Asset ephemeral storage - a Block RWX volume
D.
Automation data storage - a Block RWO volume
E.
Automation metadata storage - a File RWX volume
Full Access
Answer:
A, B
Explanation:
Before installing Automation Assets in IBM Cloud Pak for Integration (CP4I) v2021.2, specific storage types must be provisioned to support asset data and metadata storage. These storage types are required to ensure proper functioning and persistence of Automation Assets in an OpenShift-based deployment.
Asset Data Storage (File RWX Volume)
This storage is used to store asset files, which need to be accessible by multiple pods simultaneously.
It requires a shared file storage with ReadWriteMany (RWX) access mode, ensuring multiple replicas can access the data.
Example: NFS (Network File System) or OpenShift persistent storage supporting RWX.
Asset Metadata Storage (Block RWO Volume)
This storage is used for managing metadata related to automation assets.
It requires a block storage with ReadWriteOnce (RWO) access mode, which ensures exclusive access by a single node at a time for consistency.
Example: IBM Cloud Block Storage, OpenShift Container Storage (OCS) with RWO mode.
C. Asset ephemeral storage - a Block RWX volume (Incorrect)
There is no requirement for ephemeral storage in Automation Assets. Persistent storage is necessary for both asset data and metadata.
D. Automation data storage - a Block RWO volume (Incorrect)
Automation Assets specifically require file-based RWX storage for asset data, not block-based storage.
E. Automation metadata storage - a File RWX volume (Incorrect)
The metadata storage requires block-based RWO storage, not file-based RWX storage.
IBM Cloud Pak for Integration Documentation: Automation Assets Storage Requirements
IBM OpenShift Storage Documentation: Persistent Storage Configuration
IBM Cloud Block Storage: Storage Requirements for CP4I
Explanation of Incorrect Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 8
What are the two custom resources provided by IBM Licensing Operator?
A.
IBM License Collector
B.
IBM License Service Reporter
C.
IBM License Viewer
D.
IBM License Service
E.
IBM License Reporting
Full Access
Answer:
A, D
Explanation:
The IBM Licensing Operator is responsible for managing and tracking IBM software license consumption in OpenShift and Kubernetes environments. It provides two key Custom Resources (CRs) to facilitate license tracking, reporting, and compliance in IBM Cloud Pak deployments:
IBM License Collector (IBMLicenseCollector)
This custom resource is responsible for collecting license usage data from IBM Cloud Pak components and aggregating the data for reporting.
It gathers information from various IBM products deployed within the cluster, ensuring that license consumption is tracked accurately.
IBM License Service (IBMLicenseService)
This custom resource provides real-time license tracking and metering for IBM software running in a containerized environment.
It is the core service that allows administrators to query and verify license usage.
The IBM License Service ensures compliance with IBM Cloud Pak licensing requirements and integrates with the IBM License Service Reporter for extended reporting capabilities.
B. IBM License Service Reporter – Incorrect
While IBM License Service Reporter exists as an additional reporting tool, it is not a custom resource provided directly by the IBM Licensing Operator. Instead, it is a component that enhances license reporting outside the cluster.
C. IBM License Viewer – Incorrect
No such CR exists. IBM License information can be viewed through OpenShift or CLI, but there is no "License Viewer" CR.
E. IBM License Reporting – Incorrect
While reporting is a function of IBM License Service, there is no custom resource named "IBM License Reporting."
Why the other options are incorrect:
IBM Licensing Service Documentation
IBM Cloud Pak Licensing Overview
OpenShift and IBM License Service Integration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 9
Which statement is true regarding tracing in Cloud Pak for Integration?
A.
If tracing has not been enabled, the administrator can turn it on without the need to redeploy the integration capability.
B.
Distributed tracing data is enabled by default when a new capability is in-stantiated through the Platform Navigator.
C.
The administrator can schedule tracing to run intermittently for each speci-fied integration capability.
D.
Tracing for an integration capability instance can be enabled only when de-ploying the instance.
Full Access
Answer:
D
Explanation:
In IBM Cloud Pak for Integration (CP4I), distributed tracing allows administrators to monitor the flow of requests across multiple services. This feature helps in diagnosing performance issues and debugging integration flows.
Tracing must be enabled during the initial deployment of an integration capability instance.
Once deployed, tracing settings cannot be changed dynamically without redeploying the instance.
This ensures that tracing configurations are properly set up and integrated with observability tools like OpenTelemetry, Jaeger, or Zipkin.
A. If tracing has not been enabled, the administrator can turn it on without the need to redeploy the integration capability. (Incorrect)
Tracing cannot be enabled after deployment. It must be configured during the initial deployment process.
B. Distributed tracing data is enabled by default when a new capability is instantiated through the Platform Navigator. (Incorrect)
Tracing is not enabled by default. The administrator must manually enable it during deployment.
C. The administrator can schedule tracing to run intermittently for each specified integration capability. (Incorrect)
There is no scheduling option for tracing in CP4I. Once enabled, tracing runs continuously based on the chosen settings.
D. Tracing for an integration capability instance can be enabled only when deploying the instance. (Correct)
This is the correct answer. Tracing settings are defined at deployment and cannot be modified afterward without redeploying the instance.
Analysis of the Options:
IBM Cloud Pak for Integration - Tracing and Monitoring
Enabling Distributed Tracing in IBM CP4I
IBM OpenTelemetry and Jaeger Tracing Integration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 10
What are two ways an Aspera HSTS Instance can be created?
A.
Foundational Services Dashboard
B.
OpenShift console
C.
Platform Navigator
D.
IBM Aspera HSTS Installer
E.
Terraform
Full Access
Answer:
B, D
Explanation:
IBM Aspera High-Speed Transfer Server (HSTS) is a key component of IBM Cloud Pak for Integration (CP4I) that enables secure, high-speed data transfers. There are two primary methods to create an Aspera HSTS instance in CP4I v2021.2:
OpenShift Console (Option B - Correct):
Aspera HSTS can be deployed within an OpenShift cluster using the OpenShift Console.
Administrators can deploy Aspera HSTS by creating an instance from the IBM Aspera HSTS operator, which is available through the OpenShift OperatorHub.
The deployment is managed using Kubernetes custom resources (CRs) and YAML configurations.
IBM Aspera HSTS Installer (Option D - Correct):
IBM provides an installer for setting up an Aspera HSTS instance on supported platforms.
This installer automates the process of configuring the required services and dependencies.
It is commonly used for standalone or non-OpenShift deployments.
Analysis of Other Options:
Option A (Foundational Services Dashboard) - Incorrect:
The Foundational Services Dashboard is used for managing IBM Cloud Pak foundational services like identity and access management but does not provide direct deployment of Aspera HSTS.
Option C (Platform Navigator) - Incorrect:
Platform Navigator is used to manage cloud-native integrations, but it does not directly create Aspera HSTS instances. Instead, it can be used to access and manage the Aspera HSTS services after deployment.
Option E (Terraform) - Incorrect:
While Terraform can be used to automate infrastructure provisioning, IBM does not provide an official Terraform module for directly creating Aspera HSTS instances in CP4I v2021.2.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: Deploying Aspera HSTS on OpenShift
IBM Aspera Knowledge Center: Aspera HSTS Installation Guide
IBM Redbooks: IBM Cloud Pak for Integration Deployment Guide
Question # 11
What type of storage is required by the API Connect Management subsystem?
A.
NFS
B.
RWX block storage
C.
RWO block storage
D.
GlusterFS
Full Access
Answer:
C
Explanation:
In IBM API Connect, which is part of IBM Cloud Pak for Integration (CP4I), the Management subsystem requires block storage with ReadWriteOnce (RWO) access mode.
The API Connect Management subsystem handles API lifecycle management, analytics, and policy enforcement.
It requires high-performance, low-latency storage, which is best provided by block storage.
The RWO (ReadWriteOnce) access mode ensures that each persistent volume (PV) is mounted by only one node at a time, preventing data corruption in a clustered environment.
IBM Cloud Block Storage
AWS EBS (Elastic Block Store)
Azure Managed Disks
VMware vSAN
Why "RWO Block Storage" is Required?Common Block Storage Options for API Connect on OpenShift:
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. NFS
⌠Incorrect – Network File System (NFS) is a shared file storage (RWX) and does not provide the low-latency performance needed for the Management subsystem.
âŒ
B. RWX block storage
⌠Incorrect – RWX (ReadWriteMany) block storage is not supported because it allows multiple nodes to mount the volume simultaneously, leading to data inconsistency for API Connect.
âŒ
D. GlusterFS
⌠Incorrect – GlusterFS is a distributed file system, which is not recommended for API Connect’s stateful, performance-sensitive components.
âŒ
Final Answer:✅ C. RWO block storage
IBM API Connect System Requirements
IBM Cloud Pak for Integration Storage Recommendations
Red Hat OpenShift Storage Documentation
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 12
What are two capabilities of the IBM Cloud Pak foundational services operator?
A.
Messaging service to get robust and reliable messaging services.
B.
Automation assets service to store, manage, and retrieve integration assets.
C.
License Service that reports the license use of the product and its underlying product details that are deployed in the containerized environment.
D.
API management service for managing the APIs created on API Connect.
E.
IAM services for authentication and authorization.
Full Access
Answer:
C, E
Explanation:
The IBM Cloud Pak Foundational Services Operator provides essential shared services required for IBM Cloud Pak solutions, including Cloud Pak for Integration (CP4I). These foundational services enable security, licensing, monitoring, and user management across IBM Cloud Paks.
The IBM Cloud Pak Foundational Services License Service tracks and reports license usage of IBM Cloud Pak products deployed in a containerized environment.
It ensures compliance by monitoring Virtual Processor Cores (VPCs) and other licensing metrics.
This service is crucial for IBM Cloud Pak licensing audits and entitlement verification.
[Reference: IBM License Service Documentation, E. IAM Services (Authentication and Authorization)IBM Cloud Pak Foundational Services include Identity and Access Management (IAM) services, which handle:, Authentication: User and service identity verification., Authorization: Role-based access control (RBAC) for Cloud Pak components., Single Sign-On (SSO): Integration with external identity providers (LDAP, SAML, OpenID)., Reference: IBM IAM Documentation, , , Why Other Options Are Incorrect:A. Messaging service to get robust and reliable messaging services., Incorrect, because IBM Cloud Pak Foundational Services does not include a messaging service., Messaging is provided by IBM MQ (separate from Foundational Services)., B. Automation assets service to store, manage, and retrieve integration assets., Incorrect, because Automation Assets Service is part of IBM Cloud Pak for Business Automation, not Foundational Services., D. API management service for managing the APIs created on API Connect., Incorrect, because API management is handled by IBM API Connect, which is a separate component of CP4I., , , IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:, IBM Cloud Pak Foundational Services Overview, IBM Cloud Pak License Service, IBM Cloud Pak IAM Services, , ]
Question # 13
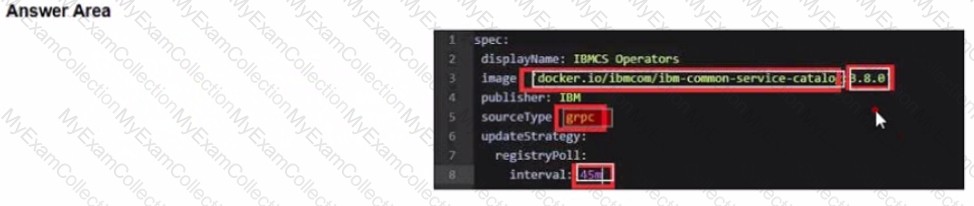
Before upgrading the Foundational Services installer version, the installer catalog source image must have the correct tag. To always use the latest catalog click on where the text 'latest' should be inserted into the image below?
Full Access
Answer:
Answer: 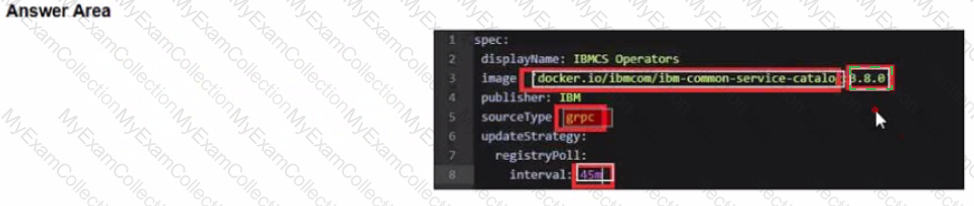
Explanation:
Upgrading from version 3.4.x and 3.5.x to version 3.6.x
Before you upgrade the foundational services installer version, make sure that the installer catalog source image has the correct tag.
If, during installation, you had set the catalog source image tag as latest, you do not need to manually change the tag.
If, during installation, you had set the catalog source image tag to a specific version, you must update the tag with the version that you want to upgrade to. Or, you can change the tag to latest to automatically complete future upgrades to the most current version.
To update the tag, complete the following actions.
To update the catalog source image tag, run the following command.
oc edit catalogsource opencloud-operators -n openshift-marketplace
Update the image tag.
Change image tag to the specific version of 3.6.x. The 3.6.3 tag is used as an example here:
spec:
displayName: IBMCS Operators
image: 'docker.io/ibmcom/ibm-common-service-catalog:3.6.3'
publisher: IBM
sourceType: grpc
updateStrategy:
registryPoll:
interval: 45m
Change the image tag to latest to automatically upgrade to the most current version.
spec:
displayName: IBMCS Operators
image: 'icr.io/cpopen/ibm-common-service-catalog:latest'
publisher: IBM
sourceType: grpc
updateStrategy:
registryPoll:
interval: 45m
To check whether the image tag is successfully updated, run the following command:
oc get catalogsource opencloud-operators -n openshift-marketplace -o jsonpath='{.spec.image}{"\n"}{.status.connectionState.lastObservedState}'
The following sample output has the image tag and its status:
icr.io/cpopen/ibm-common-service-catalog:latest
READY%
https://www.ibm.com/docs/en/cpfs?topic=online-upgrading-foundational-services-from-operator-release
Question # 14
Which statement is true about the removal of individual subsystems of API Connect on OpenShift or Cloud Pak for Integration?
A.
They can be deleted regardless of the deployment methods.
B.
They can be deleted if API Connect was deployed using a single top level CR.
C.
They cannot be deleted if API Connect was deployed using a single top level CR.
D.
They cannot be deleted if API Connect was deployed using a single top level CRM.
Full Access
Answer:
C
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying API Connect on OpenShift or within the Cloud Pak for Integration framework, there are different deployment methods:
Single Top-Level Custom Resource (CR) – This method deploys all API Connect subsystems as a single unit, meaning they are managed together. Removing individual subsystems is not supported when using this deployment method. If you need to remove a subsystem, you must delete the entire API Connect instance.
Multiple Independent Custom Resources (CRs) – This method allows more granular control, enabling the deletion of individual subsystems without affecting the entire deployment.
Since the question specifically asks about API Connect deployed using a single top-level CR, it is not possible to delete individual subsystems. The entire deployment must be deleted and reconfigured if changes are required.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM API Connect v10 Documentation: IBM Docs - API Connect on OpenShift
IBM Cloud Pak for Integration Knowledge Center: IBM CP4I Documentation
API Connect Deployment Guide: Managing API Connect Subsystems
Question # 15
What type of authentication uses an XML-based markup language to exchange identity, authentication, and authorization information between an identity provider and a service provider?
A.
Security Assertion Markup Language (SAML)
B.
IAM SSO authentication
C.
lAMviaXML
D.
Enterprise XML
Full Access
Answer:
A
Explanation:
Security Assertion Markup Language (SAML) is an XML-based standard used for exchanging identity, authentication, and authorization information between an Identity Provider (IdP) and a Service Provider (SP).
SAML is widely used for Single Sign-On (SSO) authentication in enterprise environments, allowing users to authenticate once with an identity provider and gain access to multiple applications without needing to log in again.
User Requests Access → The user tries to access a service (Service Provider).
Redirect to Identity Provider (IdP) → If not authenticated, the user is redirected to an IdP (e.g., Okta, Active Directory Federation Services).
User Authenticates with IdP → The IdP verifies user credentials.
SAML Assertion is Sent → The IdP generates a SAML assertion (XML-based token) containing authentication and authorization details.
Service Provider Grants Access → The service provider validates the SAML assertion and grants access.
How SAML Works:SAML is commonly used in IBM Cloud Pak for Integration (CP4I) v2021.2 to integrate with enterprise authentication systems for secure access control.
B. IAM SSO authentication → ⌠Incorrect
IAM (Identity and Access Management) supports SAML for SSO, but "IAM SSO authentication" is not a specific XML-based authentication standard.
C. IAM via XML → ⌠Incorrect
There is no authentication method called "IAM via XML." IBM IAM systems may use XML configurations, but IAM itself is not an XML-based authentication protocol.
D. Enterprise XML → ⌠Incorrect
"Enterprise XML" is not a standard authentication mechanism. While XML is used in many enterprise systems, it is not a dedicated authentication protocol like SAML.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration - SAML Authentication
Security Assertion Markup Language (SAML) Overview
IBM Identity and Access Management (IAM) Authentication
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 16
Which statement is true about the Authentication URL user registry in API Connect?
A.
It authenticates Developer Portal sites.
B.
It authenticates users defined in a provider organization.
C.
It authenticates Cloud Manager users.
D.
It authenticates users by referencing a custom identity provider.
Full Access
Answer:
D
Explanation:
In IBM API Connect, an Authentication URL user registry is a type of user registry that allows authentication by delegating user verification to an external identity provider. This is typically used when API Connect needs to integrate with custom authentication mechanisms, such as OAuth, OpenID Connect, or SAML-based identity providers.
When configured, API Connect does not store user credentials locally. Instead, it redirects authentication requests to the specified external authentication URL, and if the response is valid, the user is authenticated.
The Authentication URL user registry is specifically designed to reference an external custom identity provider.
This enables API Connect to integrate with external authentication systems like LDAP, Active Directory, OAuth, and OpenID Connect.
It is commonly used for single sign-on (SSO) and enterprise authentication strategies.
Why Answer D is Correct:
A. It authenticates Developer Portal sites. → Incorrect
The Developer Portal uses its own authentication mechanisms, such as LDAP, local user registries, and external identity providers, but the Authentication URL user registry does not authenticate Developer Portal users directly.
B. It authenticates users defined in a provider organization. → Incorrect
Users in a provider organization (such as API providers and administrators) are typically authenticated using Cloud Manager or an LDAP-based user registry, not via an Authentication URL user registry.
C. It authenticates Cloud Manager users. → Incorrect
Cloud Manager users are typically authenticated via LDAP or API Connect’s built-in user registry.
The Authentication URL user registry is not responsible for Cloud Manager authentication.
Explanation of Incorrect Answers:
IBM API Connect User Registry Types
IBM API Connect Authentication and User Management
IBM Cloud Pak for Integration Documentation
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
https://www.ibm.com/docs/SSMNED_v10/com.ibm.apic.cmc.doc/capic_cmc_registries_concepts.html
Question # 17
Which two authentication types are supported for single sign-on in Founda-tional Services?
A.
Basic Authentication
B.
OpenShift authentication
C.
PublicKey
D.
Enterprise SAML
E.
Local User Registry
Full Access
Answer:
B, D
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, Foundational Services provide authentication and access control mechanisms, including Single Sign-On (SSO) integration. The two supported authentication types for SSO are:
OpenShift Authentication
IBM Cloud Pak for Integration leverages OpenShift authentication to integrate with existing identity providers.
OpenShift authentication supports OAuth-based authentication, allowing users to sign in using an OpenShift identity provider, such as LDAP, OIDC, or SAML.
This method enables seamless user access without requiring additional login credentials.
Enterprise SAML (Security Assertion Markup Language)
SAML authentication allows integration with enterprise identity providers (IdPs) such as IBM Security Verify, Okta, Microsoft Active Directory Federation Services (ADFS), and other SAML 2.0-compatible IdPs.
It provides federated identity management for SSO across enterprise applications, ensuring secure access to Cloud Pak services.
A. Basic Authentication – Incorrect
Basic authentication (username and password) is not used for Single Sign-On (SSO). SSO mechanisms require identity federation through OpenID Connect (OIDC) or SAML.
C. PublicKey – Incorrect
PublicKey authentication (such as SSH key-based authentication) is used for system-level access, not for SSO in Foundational Services.
E. Local User Registry – Incorrect
While local user registries can store credentials, they do not provide SSO capabilities. SSO requires federated identity providers like OpenShift authentication or SAML-based IdPs.
Why the other options are incorrect:
IBM Cloud Pak Foundational Services Authentication Guide
OpenShift Authentication and Identity Providers
IBM Cloud Pak for Integration SSO Configuration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 18
In Cloud Pak for Integration, which user role can replace default Keys and Certificates?
A.
Cluster Manager
B.
Super-user
C.
System user
D.
Cluster Administrator
Full Access
Answer:
D
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, only a Cluster Administrator has the necessary permissions to replace default keys and certificates. This is because modifying security components such as TLS certificates affects the entire cluster and requires elevated privileges.
Access to OpenShift and Cluster-Wide Resources:
The Cluster Administrator role has full administrative control over the OpenShift cluster where CP4I is deployed.
Replacing keys and certificates often involves interacting with OpenShift secrets and security configurations, which require cluster-wide access.
Management of Certificates and Encryption:
In CP4I, certificates are used for securing communication between integration components and external systems.
Updating or replacing certificates requires privileges to modify security configurations, which only a Cluster Administrator has.
Control Over Security Policies:
CP4I security settings, including certificates, are managed at the cluster level.
Cluster Administrators ensure compliance with security policies, including certificate renewal and management.
Why is "Cluster Administrator" the Correct Answer?
Why Not the Other Options?Option
Reason for Exclusion
A. Cluster Manager
This role is typically responsible for monitoring and managing cluster resources but does not have full administrative control over security settings.
B. Super-user
There is no predefined "Super-user" role in CP4I. If referring to an elevated user, it would still require a Cluster Administrator's permissions to replace certificates.
C. System User
System users often refer to service accounts or application-level users that lack the required cluster-wide security privileges.
Thus, the Cluster Administrator role is the only one with the required access to replace default keys and certificates in Cloud Pak for Integration.
IBM Cloud Pak for Integration Security Overview
Managing Certificates in Cloud Pak for Integration
OpenShift Cluster Administrator Role
IBM Cloud Pak for Integration - Replacing Default Certificates
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 19
Select all that apply
What is the correct sequence of steps to delete IBM MQ from IBM Cloud Pak for Integration?

Full Access
Answer:
Answer: 
Explanation:
Correct Ordered Steps to Delete IBM MQ from IBM Cloud Pak for Integration (CP4I):
1ï¸âƒ£ Log in to your OpenShift cluster's web console.
Access the OpenShift web console to manage resources and installed operators.
2ï¸âƒ£ Select Operators from Installed Operators in a project containing Queue Managers.
Navigate to the Installed Operators section and locate the IBM MQ Operator in the project namespace where queue managers exist.
3ï¸âƒ£ Delete Queue Managers.
Before uninstalling the operator, delete any existing IBM MQ Queue Managers to ensure a clean removal.
4ï¸âƒ£ Uninstall the Operator.
Finally, uninstall the IBM MQ Operator from OpenShift to complete the deletion process.
To properly delete IBM MQ from IBM Cloud Pak for Integration (CP4I), the steps must be followed in the correct order:
Logging into OpenShift Web Console – This step provides access to the IBM MQ Operator and related resources.
Selecting the Installed Operator – Ensures the correct project namespace and MQ resources are identified.
Deleting Queue Managers – Queue Managers must be removed before uninstalling the operator; otherwise, orphaned resources may remain.
Uninstalling the Operator – Once all resources are removed, the MQ Operator can be uninstalled cleanly.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM MQ in Cloud Pak for Integration
Managing IBM MQ Operators in OpenShift
Uninstalling IBM MQ on OpenShift
Question # 20
The monitoring component of Cloud Pak for Integration is built on which two tools?
A.
Jaeger
B.
Prometheus
C.
Grafana
D.
Logstash
E.
Kibana
Full Access
Answer:
B, C
Explanation:
The monitoring component of IBM Cloud Pak for Integration (CP4I) v2021.2 is built on Prometheus and Grafana. These tools are widely used for monitoring and visualization in Kubernetes-based environments like OpenShift.
Prometheus – A time-series database designed for monitoring and alerting. It collects metrics from different services and components running within CP4I, enabling real-time observability.
Grafana – A visualization tool that integrates with Prometheus to create dashboards for monitoring system performance, resource utilization, and application health.
A. Jaeger → Incorrect. Jaeger is used for distributed tracing, not core monitoring.
D. Logstash → Incorrect. Logstash is used for log processing and forwarding, primarily in ELK stacks.
E. Kibana → Incorrect. Kibana is a visualization tool but is not the primary monitoring tool in CP4I; Grafana is used instead.
IBM Cloud Pak for Integration Monitoring Documentation
Prometheus Official Documentation
Grafana Official Documentation
Explanation of Other Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 21
What authentication information is provided through Base DN in the LDAP configuration process?
A.
Path to the server containing the Directory.
B.
Distinguished name of the search base.
C.
Name of the database.
D.
Configuration file path.
Full Access
Answer:
B
Explanation:
In Lightweight Directory Access Protocol (LDAP) configuration, the Base Distinguished Name (Base DN) specifies the starting point in the directory tree where searches for user authentication and group information begin. It acts as the root of the LDAP directory structure for queries.
Defines the scope of LDAP searches for user authentication.
Helps locate users, groups, and other directory objects within the directory hierarchy.
Ensures that authentication requests are performed within the correct organizational unit (OU) or domain.
Example: If users are stored in ou=users,dc=example,dc=com, then the Base DN would be:
Key Role of Base DN in Authentication:dc=example,dc=com
When an authentication request is made, LDAP searches for user entries within this Base DN to validate credentials.
A. Path to the server containing the Directory.
Incorrect, because the server path (LDAP URL) is defined separately, usually in the format:
Why Other Options Are Incorrect:ldap://ldap.example.com:389
C. Name of the database.
Incorrect, because LDAP is not a traditional relational database; it uses a hierarchical structure.
D. Configuration file path.
Incorrect, as LDAP configuration files (e.g., slapd.conf for OpenLDAP) are separate from the Base DN and are used for server settings, not authentication scope.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: LDAP Authentication Configuration
IBM Cloud Pak for Integration - Configuring LDAP
Understanding LDAP Distinguished Names (DNs)
Question # 22
An administrator is installing Cloud Pak for Integration onto an OpenShift cluster that does not have access to the internet.
How do they provide their ibm-entitlement-key when mirroring images to a portable registry?
A.
The administrator uses a cloudctl case command to configure credentials for registries which require authentication before mirroring the images.
B.
The administrator sets the key with "export ENTITLEMENTKEY" and then uses the "cloudPakOfflmelnstaller -mirror-images" script to mirror the images
C.
The administrator adds the entitlement-key to the properties file SHOME/.airgap/registries on the Bastion Host.
D.
The ibm-entitlement-key is added as a docker-registry secret onto the OpenShift cluster.
Full Access
Answer:
A
Explanation:
When installing IBM Cloud Pak for Integration (CP4I) on an OpenShift cluster that lacks internet access, an air-gapped installation is required. This process involves mirroring container images from an IBM container registry to a portable registry that can be accessed by the disconnected OpenShift cluster.
To authenticate and mirror images, the administrator must:
Use the cloudctl case command to configure credentials, including the IBM entitlement key, before initiating the mirroring process.
Authenticate with the IBM Container Registry using the entitlement key.
Mirror the required images from IBM’s registry to a local registry that the disconnected OpenShift cluster can access.
B. export ENTITLEMENTKEY and cloudPakOfflineInstaller -mirror-images
The command cloudPakOfflineInstaller -mirror-images is not a valid IBM Cloud Pak installation step.
IBM requires the use of cloudctl case commands for air-gapped installations.
C. Adding the entitlement key to .airgap/registries
There is no documented requirement to store the entitlement key in SHOME/.airgap/registries.
IBM Cloud Pak for Integration does not use this file for authentication.
D. Adding the ibm-entitlement-key as a Docker secret
While secrets are used in OpenShift for image pulling, they are not directly involved in mirroring images for air-gapped installations.
The entitlement key is required at the mirroring step, not when deploying the images.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: Installing Cloud Pak for Integration in an Air-Gapped Environment
IBM Cloud Pak Entitlement Key and Image Mirroring
OpenShift Air-Gapped Installation Guide
Question # 23
What is the result of issuing the following command?
oc get packagemanifest -n ibm-common-services ibm-common-service-operator -o*jsonpath='{.status.channels![*].name}'
A.
It lists available upgrade channels for Cloud Pak for Integration Foundational Services.
B.
It displays the status and names of channels in the default queue manager.
C.
It retrieves a manifest of services packaged in Cloud Pak for Integration operators.
D.
It returns an operator package manifest in a JSON structure.
Full Access
Answer:
A
Explanation:
jsonpath='{.status.channels[*].name}'
performs the following actions:
oc get packagemanifest → Retrieves the package manifest information for operators installed on the OpenShift cluster.
-n ibm-common-services → Specifies the namespace where IBM Common Services are installed.
ibm-common-service-operator → Targets the IBM Common Service Operator, which manages foundational services for Cloud Pak for Integration.
-o jsonpath='{.status.channels[*].name}' → Extracts and displays the available upgrade channels from the operator’s status field in JSON format.
The IBM Common Service Operator is part of Cloud Pak for Integration Foundational Services.
The status.channels[*].name field lists the available upgrade channels (e.g., stable, v1, latest).
This command helps administrators determine which upgrade paths are available for foundational services.
Why Answer A is Correct:
B. It displays the status and names of channels in the default queue manager. → Incorrect
This command is not related to IBM MQ queue managers.
It queries package manifests for IBM Common Services operators, not queue managers.
C. It retrieves a manifest of services packaged in Cloud Pak for Integration operators. → Incorrect
The command does not return a full list of services; it only displays upgrade channels.
D. It returns an operator package manifest in a JSON structure. → Incorrect
The command outputs only the names of upgrade channels in plain text, not the full JSON structure of the package manifest.
Explanation of Incorrect Answers:
IBM Cloud Pak Foundational Services Overview
OpenShift PackageManifest Command Documentation
IBM Common Service Operator Details
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 24
How can a new API Connect capability be installed in an air-gapped environ-ment?
A.
Configure a laptop or bastion host to use Container Application Software for Enterprises files to mirror images.
B.
An OVA form-factor of the Cloud Pak for Integration is recommended for high security deployments.
C.
A pass-through route must be configured in the OpenShift Container Platform to connect to the online image registry.
D.
Use secure FTP to mirror software images in the OpenShift Container Platform cluster nodes.
Full Access
Answer:
A
Explanation:
In an air-gapped environment, the OpenShift cluster does not have direct internet access, which means that new software images, such as IBM API Connect, must be manually mirrored from an external source.
The correct approach for installing a new API Connect capability in an air-gapped OpenShift environment is to:
Use a laptop or a bastion host that does have internet access to pull required container images from IBM’s entitled software registry.
Leverage Container Application Software for Enterprises (CASE) files to download and transfer images to the private OpenShift registry.
Mirror images into the OpenShift cluster by using OpenShift’s built-in image mirror utilities (oc mirror).
This method ensures that all required container images are available locally within the air-gapped environment.
Why the Other Options Are Incorrect?Option
Explanation
Correct?
B. An OVA form-factor of the Cloud Pak for Integration is recommended for high-security deployments.
⌠Incorrect – IBM Cloud Pak for Integration does not provide an OVA (Open Virtual Appliance) format for API Connect deployments. It is containerized and runs on OpenShift.
âŒ
C. A pass-through route must be configured in the OpenShift Container Platform to connect to the online image registry.
⌠Incorrect – Air-gapped environments have no internet connectivity, so this approach would not work.
âŒ
D. Use secure FTP to mirror software images in the OpenShift Container Platform cluster nodes.
⌠Incorrect – OpenShift does not use FTP for image mirroring; it relies on oc mirror and image registries for air-gapped deployments.
âŒ
Final Answer:✅ A. Configure a laptop or bastion host to use Container Application Software for Enterprises files to mirror images.
IBM API Connect Air-Gapped Installation Guide
IBM Container Application Software for Enterprises (CASE) Documentation
Red Hat OpenShift - Mirroring Images for Disconnected Environments
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 25
An administrator is checking that all components and software in their estate are licensed. They have only purchased Cloud Pak for Integration (CP41) li-censes.
How are the OpenShift master nodes licensed?
A.
CP41 licenses include entitlement for the entire OpenShift cluster that they run on, and the administrator can count against the master nodes.
B.
OpenShift master nodes do not consume OpenShift license entitlement, so no license is needed.
C.
The administrator will need to purchase additional OpenShift licenses to cover the master nodes.
D.
CP41 licenses include entitlement for 3 cores of OpenShift per core of CP41.
Full Access
Answer:
B
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, licensing is based on Virtual Processor Cores (VPCs), and it includes entitlement for OpenShift usage. However, OpenShift master nodes (control plane nodes) do not consume license entitlement, because:
OpenShift licensing only applies to worker nodes.
The master nodes (control plane nodes) manage cluster operations and scheduling, but they do not run user workloads.
IBM’s Cloud Pak licensing model considers only the worker nodes for licensing purposes.
Master nodes are essential infrastructure and are excluded from entitlement calculations.
IBM and Red Hat do not charge for OpenShift master nodes in Cloud Pak deployments.
A. CP4I licenses include entitlement for the entire OpenShift cluster that they run on, and the administrator can count against the master nodes. → ⌠Incorrect
CP4I licenses do cover OpenShift, but only for worker nodes where workloads are deployed.
Master nodes are excluded from licensing calculations.
C. The administrator will need to purchase additional OpenShift licenses to cover the master nodes. → ⌠Incorrect
No additional OpenShift licenses are required for master nodes.
OpenShift licensing only applies to worker nodes that run applications.
D. CP4I licenses include entitlement for 3 cores of OpenShift per core of CP4I. → ⌠Incorrect
The standard IBM Cloud Pak licensing model provides 1 VPC of OpenShift for 1 VPC of CP4I, not a 3:1 ratio.
Additionally, this applies only to worker nodes, not master nodes.
Explanation of Incorrect Answers:
IBM Cloud Pak Licensing Guide
IBM Cloud Pak for Integration Licensing Details
Red Hat OpenShift Licensing Guide
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 26
The following deployment topology has been created for an API Connect deploy-ment by a client.
Which two statements are true about the topology?
A.
A. Regular back-ups of the API Manager and Portal have to be taken and these backups should be replicated
to the second site.
B.
This represents a Active/Passive deployment (or Portal and Management ser-vices.
C.
This represents a distributed Kubernetes cluster across the sites.
D.
In case of Data Center J failing, the Kubernetes service of Data Center 2 will detect and instantiate the portal and management services on Data Center 2.
E.
This represents an Active/Active deployment for Gateway and Analytics services.
Full Access
Answer:
A, E
Explanation:
IBM API Connect, as part of IBM Cloud Pak for Integration (CP4I), supports various deployment topologies, including Active/Active and Active/Passive configurations across multiple data centers. Let's analyze the provided topology carefully:
Backup Strategy (Option A - Correct)
The API Manager and Developer Portal components are stateful and require regular backups.
Since the topology spans across two sites, these backups should be replicated to the second site to ensure disaster recovery (DR) and high availability (HA).
This aligns with IBM’s best practices for multi-data center deployment of API Connect.
Deployment Mode for API Manager & Portal (Option B - Incorrect)
The question suggests that API Manager and Portal are deployed across two sites.
If it were an Active/Passive deployment, only one site would be actively handling requests, while the second remains idle.
However, in IBM’s recommended architectures, API Manager and Portal are usually deployed in an Active/Active setup with proper failover mechanisms.
Cluster Type (Option C - Incorrect)
A distributed Kubernetes cluster across multiple sites would require an underlying multi-cluster federation or synchronization.
IBM API Connect is usually deployed on separate Kubernetes clusters per data center, rather than a single distributed cluster.
Therefore, this topology does not represent a distributed Kubernetes cluster across sites.
Failover Behavior (Option D - Incorrect)
Kubernetes cannot automatically detect failures in Data Center 1 and migrate services to Data Center 2 unless specifically configured with multi-cluster HA policies and disaster recovery.
Instead, IBM API Connect HA and DR mechanisms would handle failover via manual or automated orchestration, but not via Kubernetes native services.
Gateway and Analytics Deployment (Option E - Correct)
API Gateway and Analytics services are typically deployed in Active/Active mode for high availability and load balancing.
This means that traffic is dynamically routed to the available instance in both sites, ensuring uninterrupted API traffic even if one data center goes down.
Final Answer:✅ A. Regular backups of the API Manager and Portal have to be taken, and these backups should be replicated to the second site.✅ E. This represents an Active/Active deployment for Gateway and Analytics services.
IBM API Connect Deployment Topologies
IBM Documentation – API Connect Deployment Models
High Availability and Disaster Recovery in IBM API Connect
IBM API Connect HA & DR Guide
IBM Cloud Pak for Integration Architecture Guide
IBM Cloud Pak for Integration Docs
References:
Question # 27
Which two Red Hat OpenShift Operators should be installed to enable OpenShift Logging?
A.
OpenShift Console Operator
B.
OpenShift Logging Operator
C.
OpenShift Log Collector
D.
OpenShift Centralized Logging Operator
E.
OpenShift Elasticsearch Operator
Full Access
Answer:
B, E
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, logging is a critical component for monitoring cluster and application activities. To enable OpenShift Logging, two key operators must be installed:
OpenShift Logging Operator (B)
This operator is responsible for managing the logging stack in OpenShift.
It helps configure and deploy logging components like Fluentd, Kibana, and Elasticsearch within the OpenShift cluster.
It provides a unified way to collect and visualize logs across different workloads.
OpenShift Elasticsearch Operator (E)
This operator manages the Elasticsearch cluster, which is the central data store for log aggregation in OpenShift.
Elasticsearch stores logs collected from cluster nodes and applications, making them searchable and analyzable via Kibana.
Without this operator, OpenShift Logging cannot function, as it depends on Elasticsearch for log storage.
A. OpenShift Console Operator → Incorrect
The OpenShift Console Operator manages the web UI of OpenShift but has no role in logging.
It does not collect, store, or manage logs.
C. OpenShift Log Collector → Incorrect
There is no official OpenShift component or operator named "OpenShift Log Collector."
Log collection is handled by Fluentd, which is managed by the OpenShift Logging Operator.
D. OpenShift Centralized Logging Operator → Incorrect
This is not a valid OpenShift operator.
The correct operator for centralized logging is OpenShift Logging Operator.
Explanation of Incorrect Answers:
OpenShift Logging Overview
OpenShift Logging Operator Documentation
OpenShift Elasticsearch Operator Documentation
IBM Cloud Pak for Integration Logging Configuration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 28
What is one method that can be used to uninstall IBM Cloud Pak for Integra-tion?
A.
Uninstall.sh
B.
Cloud Pak for Integration console
C.
Operator Catalog
D.
OpenShift console
Full Access
Answer:
D
Explanation:
Uninstalling IBM Cloud Pak for Integration (CP4I) v2021.2 requires removing the operators, instances, and related resources from the OpenShift cluster. One method to achieve this is through the OpenShift console, which provides a graphical interface for managing operators and deployments.
The OpenShift Web Console allows administrators to:
Navigate to Operators → Installed Operators and remove CP4I-related operators.
Delete all associated custom resources (CRs) and namespaces where CP4I was deployed.
Ensure that all PVCs (Persistent Volume Claims) and secrets associated with CP4I are also deleted.
This is an officially supported method for uninstalling CP4I in OpenShift environments.
Why Option D (OpenShift Console) is Correct:
A. Uninstall.sh → ⌠Incorrect
There is no official Uninstall.sh script provided by IBM for CP4I removal.
IBM’s documentation recommends manual removal through OpenShift.
B. Cloud Pak for Integration console → ⌠Incorrect
The CP4I console is used for managing integration components but does not provide an option to uninstall CP4I itself.
C. Operator Catalog → ⌠Incorrect
The Operator Catalog lists available operators but does not handle uninstallation.
Operators need to be manually removed via the OpenShift Console or CLI.
Explanation of Incorrect Answers:
Uninstalling IBM Cloud Pak for Integration
OpenShift Web Console - Removing Installed Operators
Best Practices for Uninstalling Cloud Pak on OpenShift
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 29
Which command shows the current cluster version and available updates?
A.
update
B.
adm upgrade
C.
adm update
D.
upgrade
Full Access
Answer:
B
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on OpenShift, administrators often need to check the current cluster version and available updates before performing an upgrade.
The correct command to display the current OpenShift cluster version and check for available updates is:
oc adm upgrade
This command provides information about:
The current OpenShift cluster version.
Whether a newer version is available for upgrade.
The channel and upgrade path.
A. update – Incorrect
There is no oc update or update command in OpenShift CLI for checking cluster versions.
C. adm update – Incorrect
oc adm update is not a valid command in OpenShift. The correct subcommand is adm upgrade.
D. upgrade – Incorrect
oc upgrade is not a valid OpenShift CLI command. The correct syntax requires adm upgrade.
Why the other options are incorrect:
Example Output of oc adm upgrade:$ oc adm upgrade
Cluster version is 4.10.16
Updates available:
Version 4.11.0
Version 4.11.1
OpenShift Cluster Upgrade Documentation
IBM Cloud Pak for Integration OpenShift Upgrade Guide
Red Hat OpenShift CLI Reference
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 30
Which OpenShift component controls the placement of workloads on nodes for Cloud Pak for Integration deployments?
A.
API Server
B.
Controller Manager
C.
Etcd
D.
Scheduler
Full Access
Answer:
D
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, the component responsible for determining the placement of workloads (pods) on worker nodes is the Scheduler.
API Server (Option A): The API Server is the front-end of the OpenShift and Kubernetes control plane, handling REST API requests, authentication, and cluster state updates. However, it does not decide where workloads should be placed.
Controller Manager (Option B): The Controller Manager ensures the desired state of the system by managing controllers (e.g., ReplicationController, NodeController). It does not handle pod placement.
Etcd (Option C): Etcd is the distributed key-value store used by OpenShift and Kubernetes to store cluster state data. It plays no role in scheduling workloads.
Scheduler (Option D - Correct Answer): The Scheduler is responsible for selecting the most suitable node to run a newly created pod based on resource availability, affinity/anti-affinity rules, and other constraints.
When a new pod is created, it initially has no assigned node.
The Scheduler evaluates all worker nodes and assigns the pod to the most appropriate node, ensuring balanced resource utilization and policy compliance.
In CP4I, efficient workload placement is crucial for maintaining performance and resilience, and the Scheduler ensures that workloads are optimally distributed across the cluster.
Explanation of OpenShift Components:Why the Scheduler is Correct?IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM CP4I Documentation – Deploying on OpenShift
Red Hat OpenShift Documentation – Understanding the Scheduler
Kubernetes Documentation – Scheduler
Question # 31
Starling with Common Services 3.6, which two monitoring service modes are available?
A.
OCP Monitoring
B.
OpenShift Common Monitoring
C CP4I Monitoring
C.
CS Monitoring
D.
Grafana Monitoring
Full Access
Answer:
A, D
Explanation:
Starting with IBM Cloud Pak for Integration (CP4I) v2021.2, which uses IBM Common Services 3.6, there are two monitoring service modes available for tracking system health and performance:
OCP Monitoring (OpenShift Container Platform Monitoring) – This is the native OpenShift monitoring system that provides observability for the entire cluster, including nodes, pods, and application workloads. It uses Prometheus for metrics collection and Grafana for visualization.
CS Monitoring (Common Services Monitoring) – This is the IBM Cloud Pak for Integration-specific monitoring service, which provides additional observability features specifically for IBM Cloud Pak components. It integrates with OpenShift but focuses on Cloud Pak services and applications.
Option B (OpenShift Common Monitoring) is incorrect: While OpenShift has a Common Monitoring Stack, it is not a specific mode for IBM CP4I monitoring services. Instead, it is a subset of OCP Monitoring used for monitoring the OpenShift control plane.
Option C (CP4I Monitoring) is incorrect: There is no separate "CP4I Monitoring" service mode. CP4I relies on OpenShift's monitoring framework and IBM Common Services monitoring.
Option E (Grafana Monitoring) is incorrect: Grafana is a visualization tool, not a standalone monitoring service mode. It is used in conjunction with Prometheus in both OCP Monitoring and CS Monitoring.
IBM Cloud Pak for Integration Monitoring Documentation
IBM Common Services Monitoring Overview
OpenShift Monitoring Stack – Red Hat Documentation
Why the other options are incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 32
What role is required to install OpenShift GitOps?
A.
cluster-operator
B.
cluster-admin
C.
admin
D.
operator
Full Access
Answer:
B
Explanation:
In Red Hat OpenShift, installing OpenShift GitOps (based on ArgoCD) requires elevated cluster-wide permissions because the installation process:
Deploys Custom Resource Definitions (CRDs).
Creates Operators and associated resources.
Modifies cluster-scoped components like role-based access control (RBAC) policies.
Only a user with cluster-admin privileges can perform these actions, making cluster-admin the correct role for installing OpenShift GitOps.
Command to Install OpenShift GitOps:oc apply -f openshift-gitops-subscription.yaml
This operation requires cluster-wide permissions, which only the cluster-admin role provides.
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. cluster-operator
⌠Incorrect – No such default role exists in OpenShift. Operators are managed within namespaces but cannot install GitOps at the cluster level.
âŒ
C. admin
⌠Incorrect – The admin role provides namespace-level permissions, but GitOps requires cluster-wide access to install Operators and CRDs.
âŒ
D. operator
⌠Incorrect – This is not a valid OpenShift role. Operators are software components managed by OpenShift, but an operator role does not exist for installation purposes.
âŒ
Final Answer:✅ B. cluster-admin
Red Hat OpenShift GitOps Installation Guide
Red Hat OpenShift RBAC Roles and Permissions
IBM Cloud Pak for Integration - OpenShift GitOps Best Practices
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Question # 33
Which statement is true regarding the DataPower Gateway operator?
A.
The operator creates the DataPowerService as a DaemonSet.
B.
The operator creates the DataPowerService as a Deployment.
C.
The operator creates the DataPowerService as a StatefulSet.
D.
The operator creates the DataPowerService as a ReplicaSet.
Full Access
Answer:
C
Explanation:
In IBM Cloud Pak for Integration (CP4I) v2021.2, the DataPower Gateway operator is responsible for managing DataPower Gateway deployments within an OpenShift environment. The correct answer is StatefulSet because of the following reasons:
Persistent Identity & Storage:
A StatefulSet ensures that each DataPowerService instance has a stable, unique identity and persistent storage (e.g., for logs, configurations, and stateful data).
This is essential for DataPower since it maintains configurations that should persist across pod restarts.
Ordered Scaling & Upgrades:
StatefulSets provide ordered, predictable scaling and upgrades, which is important for enterprise gateway services like DataPower.
Network Identity Stability:
Each pod in a StatefulSet gets a stable network identity with a persistent DNS entry.
This is critical for DataPower appliances, which rely on fixed hostnames and IPs for communication.
DataPower High Availability:
StatefulSets help maintain high availability and proper state synchronization between multiple instances when deployed in an HA mode.
Why is DataPowerService created as a StatefulSet?
Why are the other options incorrect?⌠Option A (DaemonSet):
DaemonSets ensure that one pod runs on every node, which is not necessary for DataPower.
DataPower requires stateful behavior and ordered deployments, which DaemonSets do not provide.
⌠Option B (Deployment):
Deployments are stateless, while DataPower needs stateful behavior (e.g., persistence of certificates, configurations, and transaction data).
Deployments create identical replicas without preserving identity, which is not suitable for DataPower.
⌠Option D (ReplicaSet):
ReplicaSets only ensure a fixed number of running pods but do not manage stateful data or ordered scaling.
DataPower requires persistence and ordered deployment, which ReplicaSets do not support.
IBM Cloud Pak for Integration Knowledge Center – DataPower Gateway Operator
IBM Documentation
IBM DataPower Gateway Operator Overview
Official IBM Cloud documentation on how DataPower is deployed using StatefulSets in OpenShift.
Red Hat OpenShift StatefulSet Documentation
StatefulSets in Kubernetes
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:

