Question # 4
An Architect needs to design a solution for building environments for development, test, and pre-production, all located in a single Snowflake account. The environments should be based on production data.
Which solution would be MOST cost-effective and performant?
A.
Use zero-copy cloning into transient tables.
B.
Use zero-copy cloning into permanent tables.
C.
Use CREATE TABLE ... AS SELECT (CTAS) statements.
D.
Use a Snowflake task to trigger a stored procedure to copy data.
Full Access
Answer:
A
Explanation:
Zero-copy cloning is a feature in Snowflake that allows for the creation of a clone of a database, schema, or table without duplicating any data, which is cost-effective as it saves on storage costs. Transient tables are temporary and do not incur storage costs for the time they are not accessed, making them a cost-effective option for development, test, and pre-production environments that do not require the durability of permanent tables123.
References
•Snowflake Documentation on Zero-Copy Cloning3.
•Articles discussing the cost-effectiveness and performance benefits of zero-copy cloning12.
Question # 5
A Snowflake Architect is designing a multi-tenant application strategy for an organization in the Snowflake Data Cloud and is considering using an Account Per Tenant strategy.
Which requirements will be addressed with this approach? (Choose two.)
A.
There needs to be fewer objects per tenant.
B.
Security and Role-Based Access Control (RBAC) policies must be simple to configure.
C.
Compute costs must be optimized.
D.
Tenant data shape may be unique per tenant.
E.
Storage costs must be optimized.
Full Access
Answer:
B, D
Explanation:
The Account Per Tenant strategy involves creating separate Snowflake accounts for each tenant within the multi-tenant application. This approach offers a number of advantages.
Option B:With separate accounts, each tenant's environment is isolated, making security and RBAC policies simpler to configure and maintain. This is because each account can have its own set of roles and privileges without the risk of cross-tenant access or the complexity of maintaining a highly granular permission model within a shared environment.
Option D:This approach also allows for each tenant to have a unique data shape, meaning that the database schema can be tailored to the specific needs of each tenant without affecting others. This can be essential when tenants have different data models, usage patterns, or application customizations.
Question # 6
A Snowflake Architect is designing a multiple-account design strategy.
This strategy will be MOST cost-effective with which scenarios? (Select TWO).
A.
The company wants to clone a production database that resides on AWS to a development database that resides on Azure.
B.
The company needs to share data between two databases, where one must support Payment Card Industry Data Security Standard (PCI DSS) compliance but the other one does not.
C.
The company needs to support different role-based access control features for the development, test, and production environments.
D.
The company security policy mandates the use of different Active Directory instances for the development, test, and production environments.
E.
The company must use a specific network policy for certain users to allow and block given IP addresses.
Full Access
Answer:
B, D
Explanation:
B. When dealing with PCI DSS compliance, having separate accounts can be beneficial because it enables strong isolation of environments that handle sensitive data from those that do not. By segregating the compliant from non-compliant resources, an organization can limit the scope of compliance, thus making it a cost-effective strategy.
D. Different Active Directory instances can be managed more effectively and securely when separated into different accounts. This approach allows for distinct identity and access management policies, which can enforce security requirements and minimize the risk of access policy errors between environments.
Question # 7
A company wants to Integrate its main enterprise identity provider with federated authentication with Snowflake.
The authentication integration has been configured and roles have been created in Snowflake. However, the users are not automatically appearing in Snowflake when created and their group membership is not reflected in their assigned rotes.
How can the missing functionality be enabled with the LEAST amount of operational overhead?
A.
OAuth must be configured between the identity provider and Snowflake. Then the authorization server must be configured with the right mapping of users and roles.
B.
OAuth must be configured between the identity provider and Snowflake. Then the authorization server must be configured with the right mapping of users, and the resource server must be configured with the right mapping of role assignment.
C.
SCIM must be enabled between the identity provider and Snowflake. Once both are synchronized through SCIM, their groups will get created as group accounts in Snowflake and the proper roles can be granted.
D.
SCIM must be enabled between the identity provider and Snowflake. Once both are synchronized through SCIM. users will automatically get created and their group membership will be reflected as roles In Snowflake.
Full Access
Answer:
D
Explanation:
The best way to integrate an enterprise identity provider with federated authentication and enable automatic user creation and role assignment in Snowflake is to use SCIM (System for Cross-domain Identity Management). SCIM allows Snowflake to synchronize with the identity provider and create users and groups based on the information provided by the identity provider. The groups are mapped to roles in Snowflake, and the users are assigned the roles based on their group membership. This way, the identity provider remains the source of truth for user and group management, and Snowflake automatically reflects the changes without manual intervention. The other options are either incorrect or incomplete, as they involve using OAuth, which is a protocol for authorization, not authentication or user provisioning, and require additional configuration of authorization and resource servers.
Question # 8
A company’s daily Snowflake workload consists of a huge number of concurrent queries triggered between 9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the company’s Architect implement to enhance the performance of this workload? (Choose two.)
A.
Enable a multi-clustered virtual warehouse in maximized mode during the workload duration.
B.
Set the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level.
C.
Increase the size of the virtual warehouse to size X-Large.
D.
Reduce the amount of data that is being processed through this workload.
E.
Set the connection timeout to a higher value than its default.
Full Access
Answer:
A, B
Explanation:
These two configuration options can enhance the performance of the workload that consists of a huge number of concurrent queries that are smaller and faster.
Enabling a multi-clustered virtual warehouse in maximized mode allows the warehouse to scale out automatically by adding more clusters as soon as the current cluster is fully loaded, regardless of the number of queries in the queue. This can improve the concurrency and throughput of the workload by minimizing or preventing queuing. The maximized mode is suitable for workloads that require high performance and low latency, and are less sensitive to credit consumption1.
Setting the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level allows the warehouse to run more queries concurrently on each cluster. This can improve the utilization and efficiency of the warehouse resources, especially for smaller and faster queries that do not require a lot of processing power. The MAX_CONCURRENCY_LEVEL parameter can be set when creating or modifying a warehouse, and it can be changed at any time2.
Snowflake Documentation: Scaling Policy for Multi-cluster Warehouses
Snowflake Documentation: MAX_CONCURRENCY_LEVEL
Question # 9
A Snowflake Architect is designing an application and tenancy strategy for an organization where strong legal isolation rules as well as multi-tenancy are requirements.
Which approach will meet these requirements if Role-Based Access Policies (RBAC) is a viable option for isolating tenants?
A.
Create accounts for each tenant in the Snowflake organization.
B.
Create an object for each tenant strategy if row level security is viable for isolating tenants.
C.
Create an object for each tenant strategy if row level security is not viable for isolating tenants.
D.
Create a multi-tenant table strategy if row level security is not viable for isolating tenants.
Full Access
Answer:
A
Explanation:
In a scenario where strong legal isolation is required alongside the need for multi-tenancy, the most effective approach is to create separate accounts for each tenant within the Snowflake organization. This approach ensures complete isolation of data, resources, and management, adhering to strict legal and compliance requirements. Role-Based Access Control (RBAC) further enhances security by allowing granular control over who can access what resources within each account. This solution leverages Snowflake’s capabilities for managing multiple accounts under a single organization umbrella, ensuring that each tenant's data and operations are isolated from others.
[References:Snowflake documentation on multi-tenancy and account management, part of the SnowPro Advanced: Architect learning path., , , ]
Question # 10
An Architect needs to allow a user to create a database from an inbound share.
To meet this requirement, the user’s role must have which privileges? (Choose two.)
A.
IMPORT SHARE;
B.
IMPORT PRIVILEGES;
C.
CREATE DATABASE;
D.
CREATE SHARE;
E.
IMPORT DATABASE;
Full Access
Answer:
C, E
Explanation:
According to the Snowflake documentation, to create a database from an inbound share, the user’s role must have the following privileges:
The CREATE DATABASE privilege on the current account. This privilege allows the user to create a new database in the account1.
The IMPORT DATABASE privilege on the share. This privilege allows the user to import a database from the share into the account2. The other privileges listed are not relevant for this requirement. The IMPORT SHARE privilege is used to import a share into the account, not a database3. The IMPORT PRIVILEGES privilege is used to import the privileges granted on the shared objects, not the objects themselves2. The CREATE SHARE privilege is used to create a share to provide data to other accounts, not to consume data from other accounts4.
CREATE DATABASE | Snowflake Documentation
Importing Data from a Share | Snowflake Documentation
Importing a Share | Snowflake Documentation
CREATE SHARE | Snowflake Documentation
Question # 11
A company is designing its serving layer for data that is in cloud storage. Multiple terabytes of the data will be used for reporting. Some data does not have a clear use case but could be useful for experimental analysis. This experimentation data changes frequently and is sometimes wiped out and replaced completely in a few days.
The company wants to centralize access control, provide a single point of connection for the end-users, and maintain data governance.
What solution meets these requirements while MINIMIZING costs, administrative effort, and development overhead?
A.
Import the data used for reporting into a Snowflake schema with native tables. Then create external tables pointing to the cloud storage folders used for the experimentation data. Then create two different roles with grants to the different datasets to match the different user personas, and grant these roles to the corresponding users.
B.
Import all the data in cloud storage to be used for reporting into a Snowflake schema with native tables. Then create a role that has access to this schema and manage access to the data through that role.
C.
Import all the data in cloud storage to be used for reporting into a Snowflake schema with native tables. Then create two different roles with grants to the different datasets to match the different user personas, and grant these roles to the corresponding users.
D.
Import the data used for reporting into a Snowflake schema with native tables. Then create views that have SELECT commands pointing to the cloud storage files for the experimentation data. Then create two different roles to match the different user personas, and grant these roles to the corresponding users.
Full Access
Answer:
A
Explanation:
The most cost-effective and administratively efficient solution is to use a combination of native and external tables. Native tables for reporting data ensure performance and governance, while external tables allow for flexibility with frequently changing experimental data. Creating roles with specific grants to datasets aligns with the principle of least privilege, centralizing access control and simplifying user management12.
References
•Snowflake Documentation on Optimizing Cost1.
•Snowflake Documentation on Controlling Cost2.
Question # 12
What are purposes for creating a storage integration? (Choose three.)
A.
Control access to Snowflake data using a master encryption key that is maintained in the cloud provider’s key management service.
B.
Store a generated identity and access management (IAM) entity for an external cloud provider regardless of the cloud provider that hosts the Snowflake account.
C.
Support multiple external stages using one single Snowflake object.
D.
Avoid supplying credentials when creating a stage or when loading or unloading data.
E.
Create private VPC endpoints that allow direct, secure connectivity between VPCs without traversing the public internet.
F.
Manage credentials from multiple cloud providers in one single Snowflake object.
Full Access
Answer:
B, C, D
Explanation:
The purpose of creating a storage integration in Snowflake includes:
B.Store a generated identity and access management (IAM) entity for an external cloud provider- This helps in managing authentication and authorization with external cloud storage without embedding credentials in Snowflake. It supports various cloud providers like AWS, Azure, or GCP, ensuring that the identity management is streamlined across platforms.
C.Support multiple external stages using one single Snowflake object- Storage integrations allow you to set up access configurations that can be reused across multiple external stages, simplifying the management of external data integrations.
D.Avoid supplying credentials when creating a stage or when loading or unloading data- By using a storage integration, Snowflake can interact with external storage without the need to continuously manage or expose sensitive credentials, enhancing security and ease of operations.
[References:Snowflake documentation on storage integrations, found within the SnowPro Advanced: Architect course materials., , , ]
Question # 13
Which of the following are characteristics of Snowflake’s parameter hierarchy?
A.
Session parameters override virtual warehouse parameters.
B.
Virtual warehouse parameters override user parameters.
C.
Table parameters override virtual warehouse parameters.
D.
Schema parameters override account parameters.
Full Access
Answer:
B
Explanation:
In Snowflake's parameter hierarchy, virtual warehouse parameters take precedence over user parameters. This hierarchy is designed to ensure that settings at the virtual warehouse level, which typically reflect the requirements of a specific workload or set of queries, override the preferences set at the individual user level. This helps maintain consistent performance and resource utilization as specified by the administrators managing the virtual warehouses.
[References:Snowflake documentation on parameter hierarchy, found in the SnowPro Advanced: Architect learning materials., , , ]
Question # 14
A DevOps team has a requirement for recovery of staging tables used in a complex set of data pipelines. The staging tables are all located in the same staging schema. One of the requirements is to have online recovery of data on a rolling 7-day basis.
After setting up the DATA_RETENTION_TIME_IN_DAYS at the database level, certain tables remain unrecoverable past 1 day.
What would cause this to occur? (Choose two.)
A.
The staging schema has not been setup for MANAGED ACCESS.
B.
The DATA_RETENTION_TIME_IN_DAYS for the staging schema has been set to 1 day.
C.
The tables exceed the 1 TB limit for data recovery.
D.
The staging tables are of the TRANSIENT type.
E.
The DevOps role should be granted ALLOW_RECOVERY privilege on the staging schema.
Full Access
Answer:
B, D
Explanation:
The DATA_RETENTION_TIME_IN_DAYS parameter controls the Time Travel retention period for an object (database, schema, or table) in Snowflake. This parameter specifies the number of days for which historical data is preserved and can be accessed using Time Travel operations (SELECT, CREATE … CLONE, UNDROP)1.
The requirement for recovery of staging tables on a rolling 7-day basis means that the DATA_RETENTION_TIME_IN_DAYS parameter should be set to 7 at the database level. However, this parameter can be overridden at the lower levels (schema or table) if they have a different value1.
Therefore, one possible cause for certain tables to remain unrecoverable past 1 day is that the DATA_RETENTION_TIME_IN_DAYS for the staging schema has been set to 1 day. This would override the database level setting and limit the Time Travel retention period for all the tables in the schema to 1 day. To fix this, the parameter should be unset or set to 7 at the schema level1. Therefore, option B is correct.
Another possible cause for certain tables to remain unrecoverable past 1 day is that the staging tables are of the TRANSIENT type. Transient tables are tables that do not have a Fail-safe period and can have a Time Travel retention period of either 0 or 1 day. Transient tables are suitable for temporary or intermediate data that can be easily reproduced or replicated2. Tofix this, the tables should be created as permanent tables, which can have a Time Travel retention period of up to 90 days1. Therefore, option D is correct.
Option A is incorrect because the MANAGED ACCESS feature is not related to the data recovery requirement. MANAGED ACCESS is a feature that allows granting access privileges to objects without explicitly granting the privileges to roles. It does not affect the Time Travel retention period or the data availability3.
Option C is incorrect because there is no 1 TB limit for data recovery in Snowflake. The data storage size does not affect the Time Travel retention period or the data availability4.
Option E is incorrect because there is no ALLOW_RECOVERY privilege in Snowflake. The privilege required to perform Time Travel operations is SELECT, which allows querying historical data in tables5.
 Understanding & Using Time Travel : Transient Tables : Managed Access : Understanding Storage Cost : Table Privileges
Question # 15
An Architect is troubleshooting a query with poor performance using the QUERY function. The Architect observes that the COMPILATION_TIME Is greater than the EXECUTION_TIME.
What is the reason for this?
A.
The query is processing a very large dataset.
B.
The query has overly complex logic.
C.
The query Is queued for execution.
D.
The query Is reading from remote storage
Full Access
Answer:
B
Explanation:
The correct answer is B because the compilation time is the time it takes for the optimizer to create an optimal query plan for the efficient execution of the query. The compilation time depends on the complexity of the query, such as the number of tables, columns, joins, filters, aggregations, subqueries, etc. The more complex the query, the longer it takes to compile.
Option A is incorrect because the query processing time is not affected by the size of the dataset, but by the size of the virtual warehouse. Snowflake automatically scales the compute resources to match the data volume and parallelizes the query execution. The size of the dataset may affect the execution time, but not the compilation time.
Option C is incorrect because the query queue time is not part of the compilation time or the execution time. It is a separate metric that indicates how long the query waits for a warehouse slot before it starts running. The query queue time depends on the warehouse load, concurrency, and priority settings.
Option D is incorrect because the query remote IO time is not part of the compilation time or the execution time. It is a separate metric that indicates how long the query spends reading data from remote storage, such as S3 or Azure Blob Storage. The query remote IO time depends on the network latency, bandwidth, and caching efficiency. References:
Understanding Why Compilation Time in Snowflake Can Be Higher than Execution Time: This article explains why the total duration (compilation + execution) time is an essential metric to measure query performance in Snowflake. It discusses the reasons for the long compilation time, including query complexity and the number of tables and columns.
Exploring Execution Times: This document explains how to examine the past performance of queries and tasks using Snowsight or by writing queries against views in the ACCOUNT_USAGE schema. It also describes the different metrics and dimensions that affect query performance, such as duration, compilation, execution, queue, and remote IO time.
What is the “compilation time†and how to optimize it?: This community post provides some tips and best practices on how to reduce the compilation time, such as simplifying the query logic, using views or common table expressions, and avoiding unnecessary columns or joins.
Question # 16
Following objects can be cloned in snowflake
A.
Permanent table
B.
Transient table
C.
Temporary table
D.
External tables
E.
Internal stages
Full Access
Answer:
A, B, D
Explanation:
Snowflake supports cloning of various objects, such as databases, schemas, tables, stages, file formats, sequences, streams, tasks, and roles. Cloning creates a copy of an existing object in the system without copying the data or metadata. Cloning is also known as zero-copy cloning1.
Among the objects listed in the question, the following ones can be cloned in Snowflake:
Permanent table: A permanent table is a type of table that has a Fail-safe period and a Time Travel retention period of up to 90 days. A permanent table can be cloned using the CREATE TABLE … CLONE command2. Therefore, option A is correct.
Transient table: A transient table is a type of table that does not have a Fail-safe period and can have a Time Travel retention period of either 0 or 1 day. A transient table can also be cloned using the CREATE TABLE … CLONE command2. Therefore, option B is correct.
External table: An external table is a type of table that references data files stored in an external location, such as Amazon S3, Google Cloud Storage, or Microsoft Azure Blob Storage. An external table can be cloned using the CREATE EXTERNAL TABLE … CLONE command3. Therefore, option D is correct.
The following objects listed in the question cannot be cloned in Snowflake:
Temporary table: A temporary table is a type of table that is automatically dropped when the session ends or the current user logs out. Temporary tables do not support cloning4. Therefore, option C is incorrect.
Internal stage: An internal stage is a type of stage that is managed by Snowflake and stores files in Snowflake’s internal cloud storage. Internal stages do not support cloning5. Therefore, option E is incorrect.
 Cloning Considerations : CREATE TABLE … CLONE : CREATE EXTERNAL TABLE … CLONE : Temporary Tables : Internal Stages
Question # 17
Which data models can be used when modeling tables in a Snowflake environment? (Select THREE).
A.
Graph model
B.
Dimensional/Kimball
C.
Data lake
D.
lnmon/3NF
E.
Bayesian hierarchical model
F.
Data vault
Full Access
Answer:
B, D, F
Explanation:
Snowflake is a cloud data platform that supports various data models for modeling tables in a Snowflake environment. The data models can be classified into two categories: dimensional and normalized. Dimensional data models are designed to optimize query performance and ease of use for business intelligence and analytics. Normalized data models are designed to reduce data redundancy and ensure data integrity for transactional and operational systems. The following are some of the data models that can be used in Snowflake:
Dimensional/Kimball: This is a popular dimensional data model that uses a star or snowflake schema to organize data into fact and dimension tables. Fact tables store quantitative measures and foreign keys to dimension tables. Dimension tables store descriptive attributes and hierarchies. A star schema has a single denormalized dimension table for each dimension, while a snowflake schema has multiple normalized dimension tables for each dimension. Snowflake supports both star and snowflake schemas, and allows users to create views and joins to simplify queries.
Inmon/3NF: This is a common normalized data model that uses a third normal form (3NF) schema to organize data into entities and relationships. 3NF schema eliminates data duplication and ensures data consistency by applying three rules: 1) every column in a table must depend on the primary key, 2) every column in a table must depend on the whole primary key, not a part of it, and 3) every column in a table must depend only on the primary key, not on other columns. Snowflake supports 3NF schema and allows users to create referential integrity constraints and foreign key relationships to enforce data quality.
Data vault: This is a hybrid data model that combines the best practices of dimensional and normalized data models to create a scalable, flexible, and resilient data warehouse. Data vault schema consists of three types of tables: hubs, links, and satellites. Hubs store business keys and metadata for each entity. Links store associations and relationships between entities. Satellites store descriptive attributes and historical changes for each entity or relationship. Snowflake supports data vault schema and allows users to leverage its features such as time travel, zero-copy cloning, and secure data sharing to implement data vault methodology.
 What is Data Modeling? | Snowflake, Snowflake Schema in Data Warehouse Model - GeeksforGeeks, [Data Vault 2.0 Modeling with Snowflake]
Question # 18
A Data Engineer is designing a near real-time ingestion pipeline for a retail company to ingest event logs into Snowflake to derive insights. A Snowflake Architect is asked to define security best practices to configure access control privileges for the data load for auto-ingest to Snowpipe.
What are the MINIMUM object privileges required for the Snowpipe user to execute Snowpipe?
A.
OWNERSHIP on the named pipe, USAGE on the named stage, target database, and schema, and INSERT and SELECT on the target table
B.
OWNERSHIP on the named pipe, USAGE and READ on the named stage, USAGE on the target database and schema, and INSERT end SELECT on the target table
C.
CREATE on the named pipe, USAGE and READ on the named stage, USAGE on the target database and schema, and INSERT end SELECT on the target table
D.
USAGE on the named pipe, named stage, target database, and schema, and INSERT and SELECT on the target table
Full Access
Answer:
B
Explanation:
 According to the SnowPro Advanced: Architect documents and learning resources, the minimum object privileges required for the Snowpipe user to execute Snowpipe are:
OWNERSHIP on the named pipe. This privilege allows the Snowpipe user to create, modify, and drop the pipe object that defines the COPY statement for loading data from the stage to the table1.
USAGE and READ on the named stage. These privileges allow the Snowpipe user to access and read the data files from the stage that are loaded by Snowpipe2.
USAGE on the target database and schema. These privileges allow the Snowpipe user to access the database and schema that contain the target table3.
INSERT and SELECT on the target table. These privileges allow the Snowpipe user to insert data into the table and select data from the table4.
The other options are incorrect because they do not specify the minimum object privileges required for the Snowpipe user to execute Snowpipe. Option A is incorrect because it does not include the READ privilege on the named stage, which is required for the Snowpipe user to read the data files from the stage. Option C is incorrect because it does not include the OWNERSHIP privilege on the named pipe, which is required for the Snowpipe user to create, modify, and drop the pipe object. Option D is incorrect because it does not include the OWNERSHIP privilege on the named pipe or the READ privilege on the named stage, which are both required for the Snowpipe user to execute Snowpipe. References: CREATE PIPE | Snowflake Documentation, CREATE STAGE | Snowflake Documentation, CREATE DATABASE | Snowflake Documentation, CREATE TABLE | Snowflake Documentation
Question # 19
Company A would like to share data in Snowflake with Company B. Company B is not on the same cloud platform as Company A.
What is required to allow data sharing between these two companies?
A.
Create a pipeline to write shared data to a cloud storage location in the target cloud provider.
B.
Ensure that all views are persisted, as views cannot be shared across cloud platforms.
C.
Setup data replication to the region and cloud platform where the consumer resides.
D.
Company A and Company B must agree to use a single cloud platform: Data sharing is only possible if the companies share the same cloud provider.
Full Access
Answer:
C
Explanation:
 According to the SnowPro Advanced: Architect documents and learning resources, the requirement to allow data sharing between two companies that are not on the same cloud platform is to set up data replication to the region and cloud platform where the consumer resides. Data replication is a feature of Snowflake that enables copying databases across accounts in different regions and cloud platforms. Data replication allows data providers to securely share data with data consumers across different regions and cloud platforms by creating a replica database in the consumer’s account. The replica database is read-only and automatically synchronized with the primary database in the provider’s account. Data replication is useful for scenarios where data sharing is not possible or desirable due to latency, compliance, or security reasons1. The other options are incorrect because they are not required or feasible to allow data sharing between two companies that are not on the same cloud platform. Option A is incorrect because creating a pipeline to write shared data to a cloud storage location in the target cloud provider is not a secure or efficient way of sharing data. It would require additional steps to load the data from the cloud storage to the consumer’s account, and it would not leverage the benefits of Snowflake’s data sharing features. Option B is incorrect because ensuring that all views are persisted is not relevant for data sharing across cloud platforms. Views can be shared across cloud platforms as long as they reference objects in the same database. Persisting views is an option to improve the performance of querying views, but it is notrequired for data sharing2. Option D is incorrect because Company A and Company B do not need to agree to use a single cloud platform. Data sharing is possible across different cloud platforms using data replication or other methods, such as listings or auto-fulfillment3. References: ReplicatingDatabases Across Multiple Accounts | Snowflake Documentation, Persisting Views | Snowflake Documentation, Sharing Data Across Regions and Cloud Platforms | Snowflake Documentation
Question # 20
Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
A.
Choose columns that are frequently used in join predicates.
B.
Choose lower cardinality columns to support clustering keys and cost effectiveness.
C.
Choose TIMESTAMP columns with nanoseconds for the highest number of unique rows.
D.
Choose cluster columns that are most actively used in selective filters.
E.
Choose cluster columns that are actively used in the GROUP BY clauses.
Full Access
Answer:
A, D
Explanation:
 According to the Snowflake documentation, the best practices for choosing clustering keys are:
Choose columns that are frequently used in join predicates. This can improve the join performance by reducing the number of micro-partitions that need to be scanned and joined.
Choose columns that are most actively used in selective filters. This can improve the scan efficiency by skipping micro-partitions that do not match the filter predicates.
Avoid using low cardinality columns, such as gender or country, as clustering keys. This can result in poor clustering and high maintenance costs.
Avoid using TIMESTAMP columns with nanoseconds, as they tend to have very high cardinality and low correlation with other columns. This can also result in poor clustering and high maintenance costs.
Avoid using columns with duplicate values or NULLs, as they can cause skew in the clustering and reduce the benefits of pruning.
Cluster on multiple columns if the queries use multiple filters or join predicates. This can increase the chances of pruning more micro-partitions and improve the compression ratio.
Clustering is not always useful, especially for small or medium-sized tables, or tables that are not frequently queried or updated. Clustering can incur additional costs for initially clustering the data and maintaining the clustering over time.
Clustering Keys & Clustered Tables | Snowflake Documentation
[Considerations for Choosing Clustering for a Table | Snowflake Documentation]
Question # 21
Which Snowflake objects can be used in a data share? (Select TWO).
A.
Standard view
B.
Secure view
C.
Stored procedure
D.
External table
E.
Stream
Full Access
Answer:
B, D
Explanation:
https://docs.snowflake.com/en/user-guide/data-sharing-intro
Question # 22
What is a key consideration when setting up search optimization service for a table?
A.
Search optimization service works best with a column that has a minimum of 100 K distinct values.
B.
Search optimization service can significantly improve query performance on partitioned external tables.
C.
Search optimization service can help to optimize storage usage by compressing the data into a GZIP format.
D.
The table must be clustered with a key having multiple columns for effective search optimization.
Full Access
Answer:
A
Explanation:
A. The Search Optimization Service is designed to accelerate the performance of queries that use filters on large tables. One of the key considerations for its effectiveness is using it with tables where the columns used in the filter conditions have a high number of distinct values, typically in the hundreds of thousands or more. This is because the service creates a map-reduce-like index on the column to speed up queries that use point lookups or range scans on that column. The more unique values there are, the more effective the index is at narrowing down the search space.
[References:Snowflake documentation and best practices on the Search Optimization Service, which would be covered under the SnowPro Advanced: Architect certification materials., , , ]
Question # 23
Which Snowflake data modeling approach is designed for BI queries?
A.
3 NF
B.
Star schema
C.
Data Vault
D.
Snowflake schema
Full Access
Answer:
B
Explanation:
In the context of business intelligence (BI) queries, which are typically focused on data analysis and reporting, the star schema is the most suitable data modeling approach.
Option B: Star Schema- The star schema is a type of relational database schema that is widely used for developing data warehouses and data marts for BI purposes. It consists of a central fact table surrounded by dimension tables. The fact table contains the core data metrics, and the dimension tables contain descriptive attributes related to the fact data. The simplicity of the star schema allows for efficient querying and aggregation, which are common operations in BI reporting.
Question # 24
An event table has 150B rows and 1.5M micro-partitions, with the following statistics:
Column NDV*
A_ID 11K
C_DATE 110
NAME 300K
EVENT_ACT_0 1.1G
EVENT_ACT_4 2.2G
*NDV = Number of Distinct Values
What three clustering keys should be used, in order?
A.
C_DATE, A_ID, NAME
B.
A_ID, NAME, C_DATE
C.
C_DATE, A_ID, EVENT_ACT_0
D.
C_DATE, A_ID, EVENT_ACT_4
Full Access
Answer:
C
Explanation:
Comprehensive and Detailed 150 to 250 words of Explanation From Snowflake SnowPro Architect exam scope and all publicly documented material:
Clustering keys are most beneficial when they improve micro-partition pruning for common filter patterns and when the chosen columns provide a useful ordering that co-locates data. A common heuristic is to place lower-cardinality columns earlier (to quickly narrow partitions) and then add a higher-cardinality column that further reduces scanned partitions for selective access paths. Here, C_DATE has very low NDV (110), making it an excellent leading key to organize data by date and enable strong pruning for time-bound queries typical of event tables. Next, A_ID (11K) is moderate cardinality and can further segment data within a date range, helping point lookups or narrow scans by identifier. For the third key, the options force choosing between very high-cardinality event activity columns; selecting EVENT_ACT_0 (1.1G) is preferable to EVENT_ACT_4 (2.2G) because it is comparatively less distinct while still supporting additional pruning when queries filter by that attribute. This ordering aligns with Snowflake guidance: keep keys few, ordered to match common predicates, and avoid excessively high-cardinality keys unless they directly match frequent selective filters.
=========
QUESTION NO: 2 [Performance Optimization and Monitoring]
An Architect has implemented the search optimization service for a table. A user adds a new column to the table and there is a decrease in query performance. The Architect executes the DESCRIBE SEARCH OPTIMIZATION command and finds that the newly added column was not included in the search access path. Why did this occur?
A. The new column has a data type that is not supported by the search optimization service.
B. The new column is automatically included in the search access path, but there is a time delay before it takes effect.
C. The ON clause was used when enabling the search optimization service, which does not automatically include new columns.
D. The search optimization property needs to be dropped and then added back for the changes to take effect.
Answer: C
Comprehensive and Detailed 150 to 250 words of Explanation From Snowflake SnowPro Architect exam scope and all publicly documented material:
Search Optimization Service (SOS) builds and maintains a “search access path†for predicates on specific columns. When SOS is enabled without specifying columns, Snowflake can manage broader coverage depending on configuration; however, if SOS is enabled using an ON clause (targeting particular columns/expressions), the access path is explicitly defined and does not automatically expand to include newly added columns. That means queries filtering on the new column won’t benefit from SOS, and if workload patterns shift toward that column, perceived performance can drop relative to expectations. DESCRIBE SEARCH OPTIMIZATION exposing that the new column is absent from the access path is consistent with SOS being configured for a fixed set of columns. In SnowPro Architect terms, this is an operational/design consideration: SOS requires deliberate selection of access paths aligned to query predicates, and schema evolution (adding columns) may require revisiting SOS configuration to include new predicates that matter. This also reinforces the cost/performance tradeoff: SOS accelerates selective point-lookups and highly selective filters, but it must be targeted and maintained as query patterns and schemas change.
=========
QUESTION NO: 3 [Architecting Snowflake Solutions]
An Architect is defining transaction rules to adhere to ACID properties to ensure that executed statements are either committed or rolled back. Based on this scenario, what characteristics of transactions should be considered? (Select TWO).
A. The autocommit setting can be changed inside a stored procedure.
B. Explicit transactions should contain DDL, DML, and query statements.
C. Explicit transactions should contain only DML statements and query statements. All DDL statements implicitly commit active transactions.
D. An explicit transaction can be started by executing a BEGIN WORK statement and can be ended by executing a COMMIT WORK statement.
E. An explicit transaction can be started by executing a BEGIN TRANSACTION statement and can be ended by executing an END TRANSACTION statement.
Answer: C, D
Comprehensive and Detailed 150 to 250 words of Explanation From Snowflake SnowPro Architect exam scope and all publicly documented material:
Snowflake supports transactional behavior for DML (and SELECT statements within a transaction context), but DDL statements have special behavior: many DDL operations implicitly commit the current transaction. Because of that, mixing DDL with DML inside an explicit transaction undermines the “all-or-nothing†rollback expectations and complicates ACID-driven rules. Therefore, a key design characteristic is that explicit transactions should generally be limited to DML and query statements, while recognizing that DDL can implicitly commit and break transactional boundaries (Choice C). Additionally, Snowflake supports explicit transaction control statements using standard SQL forms; BEGIN WORK and COMMIT WORK are valid ways to open and close an explicit transaction (Choice D). From an architecting standpoint, this matters for pipeline design, error handling, and idempotency: multi-step loads/merges should group logically atomic DML steps into an explicit transaction so they commit together or roll back together, but DDL (like CREATE/ALTER) should be separated or executed with full awareness of implicit commits. This is consistent with SnowPro Architect expectations around reliable data engineering patterns and correctness under failure.
=========
QUESTION NO: 4 [Snowflake Data Engineering]
A Snowflake account has the following parameters:
MIN_DATA_RETENTION_TIME_IN_DAYS is set to 5 at the account level.
DATA_RETENTION_TIME_IN_DAYS is set to 4 on database DB1, and 6 on Schema1 in DB1.
DATA_RETENTION_TIME_IN_DAYS is set to 5 on database DB2, and 8 on Schema2 in DB2.What will be the result?
A. DB1 and Schema1 retained 5 days; DB2 and Schema2 retained 5 days.
B. DB1 and Schema1 retained 4 days; DB2 and Schema2 retained 5 days.
C. DB1 retained 4 days and Schema1 6 days; DB2 retained 5 days and Schema2 8 days.
D. DB1 retained 5 days and Schema1 6 days; DB2 retained 5 days and Schema2 8 days.
Answer: D
Comprehensive and Detailed 150 to 250 words of Explanation From Snowflake SnowPro Architect exam scope and all publicly documented material:
Snowflake Time Travel retention is governed by a parameter hierarchy and by edition-dependent limits, but the key behavior in this scenario is the minimum retention guardrail. MIN_DATA_RETENTION_TIME_IN_DAYS sets a floor: objects cannot effectively use a DATA_RETENTION_TIME_IN_DAYS value below that minimum. With an account-level minimum of 5 days, a database-level setting of 4 days is below the permitted minimum, so the effective retention for DB1 cannot be 4 days; it must be at least 5 days. Meanwhile, Schema1 is set to 6 days, which is above the minimum and should apply at the schema level (schemas can override their parent database settings within allowed bounds). For DB2, the database setting is 5 days, which matches the minimum and is valid; Schema2 at 8 days is also valid and applies to objects under that schema where applicable. From an architectural and operational perspective, this highlights two exam-relevant points: (1) retention is controlled via hierarchical parameters (account → database → schema → table), and (2) minimum retention settings enforce governance constraints across environments, preventing overly aggressive reductions that might violate recovery requirements.
=========
QUESTION NO: 5 [Performance Optimization and Monitoring]
An Architect has configured the search optimization service on a table, but metrics show that performance of a number of regularly executed queries is not improving. What could be causing this? (Select TWO).
A. The queries contain SEARCH functions.
B. The queries exceed the predicate limit.
C. The queries contain a predicate mismatch.
D. The queries are running against tables that contain semi-structured data.
E. The queries have a scalar subquery that queries the same table as the table in an outer query.
Answer: B, C
Comprehensive and Detailed 150 to 250 words of Explanation From Snowflake SnowPro Architect exam scope and all publicly documented material:
Search Optimization Service improves performance by maintaining additional search structures to accelerate selective predicates for supported query patterns. Two common reasons it may not help are (1) exceeding the predicate limit and (2) predicate mismatch. If queries include more predicates than SOS can leverage effectively (or beyond documented limits for the access path), Snowflake may not apply the optimization and will revert to normal micro-partition pruning and scanning behavior (Choice B). Predicate mismatch occurs when the query’s filter conditions do not align with the SOS access path definition—examples include using different columns than those optimized, applying functions/casts that prevent using the access path, or using non-supported predicate forms—so SOS cannot accelerate those queries (Choice C). Semi-structured data alone does not inherently prevent SOS benefits; SOS can be used with certain patterns, including on some expressions, but it still must match the configured access path. Likewise, the presence of SEARCH functions is not the core issue; SOS is about access paths and supported predicates, not requiring SEARCH() usage. Architecturally, this is why SOS should be selectively enabled for columns and predicate shapes that dominate high-cost workloads, and monitored/adjusted as query patterns evolve.
Question # 25
When loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP() what will occur?
A.
All rows loaded using a specific COPY statement will have varying timestamps based on when the rows were inserted.
B.
Any rows loaded using a specific COPY statement will have varying timestamps based on when the rows were read from the source.
C.
Any rows loaded using a specific COPY statement will have varying timestamps based on when the rows were created in the source.
D.
All rows loaded using a specific COPY statement will have the same timestamp value.
Full Access
Answer:
D
Explanation:
 According to the Snowflake documentation, when loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP(), the default value is evaluated once per COPY statement, not once per row. Therefore, all rows loaded using a specific COPY statement will have the same timestamp value. This behavior ensures that the timestamp value reflects the time when the data was loaded into the table, not when the data was read from the source or created in the source. References:
Snowflake Documentation: Loading Data into Tables with Default Values
Snowflake Documentation: COPY INTO table
Question # 26
An Architect would like to save quarter-end financial results for the previous six years.
Which Snowflake feature can the Architect use to accomplish this?
A.
Search optimization service
B.
Materialized view
C.
Time Travel
D.
Zero-copy cloning
E.
Secure views
Full Access
Answer:
D
Explanation:
Zero-copy cloning is a Snowflake feature that can be used to save quarter-end financial results for the previous six years. Zero-copy cloning allows creating a copy of a database, schema, table, or view without duplicating the data or metadata. The clone shares the same data files as the original object, but tracks any changes made to the clone or the original separately. Zero-copy cloning can be used to create snapshots of data at different points in time, such as quarter-end financial results, and preserve them for future analysis or comparison. Zero-copy cloning is fast, efficient, and does not consume any additional storage space unless the data is modified1.
Zero-Copy Cloning | Snowflake Documentation
Question # 27
A company has a Snowflake account named ACCOUNTA in AWS us-east-1 region. The company stores its marketing data in a Snowflake database named MARKET_DB. One of the company’s business partners has an account named PARTNERB in Azure East US 2 region. For marketing purposes the company has agreed to share the database MARKET_DB with the partner account.
Which of the following steps MUST be performed for the account PARTNERB to consume data from the MARKET_DB database?
A.
Create a new account (called AZABC123) in Azure East US 2 region. From account ACCOUNTA create a share of database MARKET_DB, create a new database out of this share locally in AWS us-east-1 region, and replicate this new database to AZABC123 account. Then set up data sharing to the PARTNERB account.
B.
From account ACCOUNTA create a share of database MARKET_DB, and create a new database out of this share locally in AWS us-east-1 region. Then make this database the provider and share it with the PARTNERB account.
C.
Create a new account (called AZABC123) in Azure East US 2 region. From account ACCOUNTA replicate the database MARKET_DB to AZABC123 and from this account set up the data sharing to the PARTNERB account.
D.
Create a share of database MARKET_DB, and create a new database out of this share locally in AWS us-east-1 region. Then replicate this database to the partner’s account PARTNERB.
Full Access
Answer:
C
Explanation:
Snowflake supports data sharing across regions and cloud platforms using account replication and share replication features. Account replication enables the replication of objects from a source account to one or more target accounts in the same organization. Share replication enables the replication of shares from a source account to one or more target accounts in the same organization1.
To share data from the MARKET_DB database in the ACCOUNTA account in AWS us-east-1 region with the PARTNERB account in Azure East US 2 region, the following steps must be performed:
Create a new account (called AZABC123) in Azure East US 2 region. This account will act as a bridge between the source and the target accounts. The new account must be linked to the ACCOUNTA account using an organization2.
From the ACCOUNTA account, replicate the MARKET_DB database to the AZABC123 account using the account replication feature. This will create a secondary database in the AZABC123 account that is a replica of the primary database in the ACCOUNTA account3.
From the AZABC123 account, set up the data sharing to the PARTNERB account using the share replication feature. This will create a share of the secondary database in the AZABC123 account and grant access to the PARTNERB account. The PARTNERB account can then create a database from the share and query the data4.
Therefore, option C is the correct answer.
 Replicating Shares Across Regions and Cloud Platforms : Working with Organizations and Accounts : Replicating Databases Across Multiple Accounts : Replicating Shares Across Multiple Accounts
Question # 28
An Architect is designing Snowflake architecture to support fast Data Analyst reporting. To optimize costs, the virtual warehouse is configured to auto-suspend after 2 minutes of idle time. Queries are run once in the morning after refresh, but later queries run slowly.
Why is this occurring?
A.
The warehouse is not large enough.
B.
The warehouse was not configured as a multi-cluster warehouse.
C.
The warehouse was not created with USE_CACHE = TRUE.
D.
When the warehouse was suspended, the cache was dropped.
Full Access
Answer:
D
Explanation:
Snowflake virtual warehouses maintain a local result and data cache only while the warehouse is running. When a warehouse is suspended—whether manually or via auto-suspend—the local cache is cleared. As a result, subsequent queries cannot benefit from cached data and must re-scan data from remote storage, leading to slower execution (Answer D).
Snowflake does maintain a global result cache at the cloud services layer, but it is only used when the exact same query text is re-executed and the underlying data has not changed. In many analytical workloads, queries vary slightly, preventing reuse of the result cache.
Warehouse size and multi-cluster configuration impact concurrency and throughput, not cache persistence. There is no USE_CACHE parameter in Snowflake. This question tests an architect’s understanding of Snowflake caching behavior and the tradeoff between aggressive auto-suspend for cost control and cache reuse for performance.
=========
QUESTION NO: 32 [Security and Access Management]
A company has two databases, DB1 and DB2.
Role R1 has SELECT on DB1.
Role R2 has SELECT on DB2.
Users should normally access only one database, but a small group must access both databases in the same query with minimal operational overhead.
What is the best approach?
A. Set DEFAULT_SECONDARY_ROLE to R2.
B. Grant R2 to users and use USE_SECONDARY_ROLES for SELECT.
C. Grant R2 to R1 to use privilege inheritance.
D. Grant R2 to users and require USE SECONDARY ROLES.
Answer: B
Snowflake supports secondary roles to allow users to activate additional privileges without changing their primary role. Granting R2 to the users and enabling USE_SECONDARY_ROLES for SELECT allows those users to access both DB1 and DB2 in a single query, while keeping their default role unchanged (Answer B).
This approach minimizes operational overhead because it avoids role restructuring or privilege inheritance changes. It also maintains least privilege by ensuring that users only activate additional access when needed. Setting a default secondary role applies automatically and may unintentionally broaden access. Granting R2 to R1 affects all users with R1, which violates the requirement to limit access to a small group.
This pattern is a common SnowPro Architect design for cross-database access control.
=========
QUESTION NO: 33 [Performance Optimization and Monitoring]
How can an Architect enable optimal clustering to enhance performance for different access paths on a given table?
A. Create multiple clustering keys for a table.
B. Create multiple materialized views with different cluster keys.
C. Create super projections that automatically create clustering.
D. Create a clustering key containing all access path columns.
Answer: B
Snowflake allows only one clustering key per table, which limits its effectiveness when multiple access paths exist. Creating a composite clustering key that includes many columns often leads to poor clustering depth and limited pruning.
Materialized views provide an effective alternative. Each materialized view can be clustered independently, allowing architects to tailor physical data organization to specific query patterns (Answer B). Queries targeting different access paths can then leverage the appropriate materialized view, achieving better pruning and performance.
Super projections are not a Snowflake feature. Creating multiple clustering keys on a single table is not supported. This question reinforces SnowPro Architect knowledge of advanced performance design techniques using materialized views.
=========
QUESTION NO: 34 [Cost Control and Resource Management]
An Architect configures the following timeouts and creates a task using a size X-Small warehouse. The task’s INSERT statement will take ~40 hours.
How long will the INSERT execute?
A. 1 minute
B. 5 minutes
C. 1 hour
D. 40 hours
Answer: A
Tasks in Snowflake are governed by the USER_TASK_TIMEOUT_MS parameter, which specifies the maximum execution time for a single task run. In this scenario, USER_TASK_TIMEOUT_MS = 60000, which equals 1 minute. This timeout applies regardless of account-, session-, or warehouse-level statement timeout settings.
Even though the account, session, and warehouse statement timeouts are higher, the task-specific timeout takes precedence for task execution. As a result, the INSERT statement will be terminated after 1 minute (Answer A).
This is a key SnowPro Architect concept: tasks have their own execution limits that override other timeout parameters. Architects must ensure that task timeouts are configured appropriately for long-running operations or redesign workloads to fit within task constraints.
=========
QUESTION NO: 35 [Snowflake Ecosystem and Integrations]
Several in-house applications need to connect to Snowflake without browser access or redirect capabilities.
What is the Snowflake best practice for authentication?
A. Use Snowflake OAuth.
B. Use usernames and passwords.
C. Use external OAuth.
D. Use key pair authentication with a service user.
Answer: D
For non-interactive, service-to-service authentication scenarios, Snowflake recommends key pair authentication using a service user (Answer D). This method avoids hardcoding passwords, supports automated rotation of credentials, and aligns with security best practices.
OAuth-based methods typically require browser redirects or user interaction, which are not available in this scenario. Username/password authentication introduces security risks and operational overhead.
Key pair authentication enables strong, certificate-based security and is widely used in SnowPro Architect designs for applications, ETL tools, and automated workloads.
Question # 29
A retail company has over 3000 stores all using the same Point of Sale (POS) system. The company wants to deliver near real-time sales results to category managers. The stores operate in a variety of time zones and exhibit a dynamic range of transactions each minute, with some stores having higher sales volumes than others.
Sales results are provided in a uniform fashion using data engineered fields that will be calculated in a complex data pipeline. Calculations include exceptions, aggregations, and scoring using external functions interfaced to scoring algorithms. The source data for aggregations has over 100M rows.
Every minute, the POS sends all sales transactions files to a cloud storage location with a naming convention that includes store numbers and timestamps to identify the set of transactions contained in the files. The files are typically less than 10MB in size.
How can the near real-time results be provided to the category managers? (Select TWO).
A.
All files should be concatenated before ingestion into Snowflake to avoid micro-ingestion.
B.
A Snowpipe should be created and configured with AUTO_INGEST = true. A stream should be created to process INSERTS into a single target table using the stream metadata to inform the store number and timestamps.
C.
A stream should be created to accumulate the near real-time data and a task should be created that runs at a frequency that matches the real-time analytics needs.
D.
An external scheduler should examine the contents of the cloud storage location and issue SnowSQL commands to process the data at a frequency that matches the real-time analytics needs.
E.
The copy into command with a task scheduled to run every second should be used to achieve the near-real time requirement.
Full Access
Answer:
B, C
Explanation:
To provide near real-time sales results to category managers, the Architect can use the following steps:
Create an external stage that references the cloud storage location where the POS sends the sales transactions files. The external stage should use the file format and encryption settings that match the source files2
Create a Snowpipe that loads the files from the external stage into a target table in Snowflake. The Snowpipe should be configured with AUTO_INGEST = true, which means that it will automatically detect and ingest new files as they arrive in the external stage. The Snowpipe should also use a copy option to purge the files from the external stage after loading, to avoid duplicate ingestion3
Create a stream on the target table that captures the INSERTS made by the Snowpipe. The stream should include the metadata columns that provide information about the file name, path, size, and last modified time. The stream should also have a retention period that matches the real-time analytics needs4
Create a task that runs a query on the stream to process the near real-time data. The query should use the stream metadata to extract the store number and timestamps from the file name and path, and perform the calculations for exceptions, aggregations, and scoring using external functions. The query should also output the results to another table or view that can be accessed by the category managers. The task should be scheduled to run at a frequency that matches the real-time analytics needs, such as every minute or every 5 minutes.
The other options are not optimal or feasible for providing near real-time results:
All files should be concatenated before ingestion into Snowflake to avoid micro-ingestion. This option is not recommended because it would introduce additional latency and complexity in the data pipeline. Concatenating files would require an external process or service that monitors the cloud storage location and performs the file merging operation. This would delay the ingestion of new files into Snowflake and increase the risk of data loss or corruption. Moreover, concatenating files would not avoid micro-ingestion, as Snowpipe would still ingest each concatenated file as a separate load.
An external scheduler should examine the contents of the cloud storage location and issue SnowSQL commands to process the data at a frequency that matches the real-time analytics needs. This option is not necessary because Snowpipe can automatically ingest new files from the external stage without requiring an external trigger or scheduler. Using an external scheduler would add more overhead and dependency to the data pipeline, and it would not guarantee near real-time ingestion, as it would depend on the polling interval and the availability of the external scheduler.
The copy into command with a task scheduled to run every second should be used to achieve the near-real time requirement. This option is not feasible because tasks cannot be scheduled to run every second in Snowflake. The minimum interval for tasks is one minute, and even that is not guaranteed, as tasks are subject to scheduling delays and concurrency limits. Moreover, using the copy into command with a task would not leverage the benefits of Snowpipe, such as automatic file detection, load balancing, and micro-partition optimization. References:
1: SnowPro Advanced: Architect | Study Guide
2: Snowflake Documentation | Creating Stages
3: Snowflake Documentation | Loading Data Using Snowpipe
4: Snowflake Documentation | Using Streams and Tasks for ELT
Snowflake Documentation | Creating Tasks
Snowflake Documentation | Best Practices for Loading Data
Snowflake Documentation | Using the Snowpipe REST API
Snowflake Documentation | Scheduling Tasks
 SnowPro Advanced: Architect | Study Guide
 Creating Stages
 Loading Data Using Snowpipe
 Using Streams and Tasks for ELT
[Creating Tasks]
[Best Practices for Loading Data]
[Using the Snowpipe REST API]
[Scheduling Tasks]
Question # 30
The following statements have been executed successfully:
USE ROLE SYSADMIN;
CREATE OR REPLACE DATABASE DEV_TEST_DB;
CREATE OR REPLACE SCHEMA DEV_TEST_DB.SCHTEST WITH MANAGED ACCESS;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE ANALYST_PROJ;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE ANALYST_PROJ;
GRANT CREATE TABLE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
USE ROLE DEV_PROJ_OWN;
CREATE OR REPLACE TABLE DEV_TEST_DB.SCHTEST.CURRENCY (
COUNTRY VARCHAR(255),
CURRENCY_NAME VARCHAR(255),
ISO_CURRENCY_CODE VARCHAR(15),
CURRENCY_CD NUMBER(38,0),
MINOR_UNIT VARCHAR(255),
WITHDRAWAL_DATE VARCHAR(255)
);
The role hierarchy is as follows (simplified from the diagram):
ACCOUNTADMIN└─ DEV_SYSADMIN└─ DEV_PROJ_OWN└─ ANALYST_PROJ
Separately:
ACCOUNTADMIN└─ SYSADMIN└─ MAPPING_ROLE
Which statements will return the records from the table
DEV_TEST_DB.SCHTEST.CURRENCY? (Select TWO)
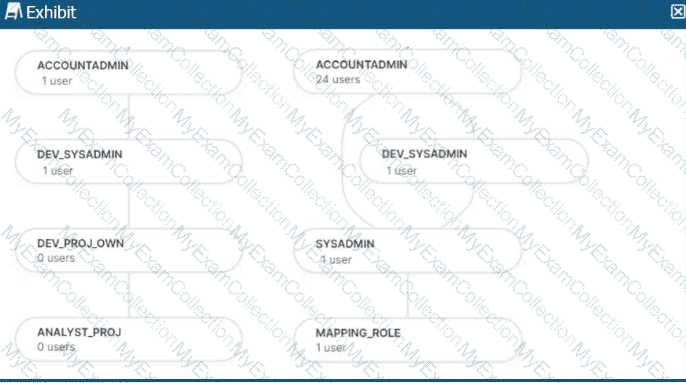
A.
USE ROLE DEV_PROJ_OWN;
GRANT SELECT ON DEV_TEST_DB.SCHTEST.CURRENCY TO ROLE ANALYST_PROJ;
USE ROLE ANALYST_PROJ;
SELECT * FROM DEV_TEST_DB.SCHTEST.CURRENCY;
B.
USE ROLE DEV_PROJ_OWN;
SELECT * FROM DEV_TEST_DB.SCHTEST.CURRENCY;
C.
USE ROLE SYSADMIN;
SELECT * FROM DEV_TEST_DB.SCHTEST.CURRENCY;
D.
USE ROLE MAPPING_ROLE;
SELECT * FROM DEV_TEST_DB.SCHTEST.CURRENCY;
E.
USE ROLE ACCOUNTADMIN;
SELECT * FROM DEV_TEST_DB.SCHTEST.CURRENCY;
Full Access
Answer:
A, B
Explanation:
This question evaluates deep understanding of Snowflake RBAC, managed access schemas, and privilege inheritance, all of which are core SnowPro Architect topics. The schema DEV_TEST_DB.SCHTEST is created WITH MANAGED ACCESS, meaning that only the schema owner (or a higher role in the hierarchy) can grant object privileges such as SELECT on tables within the schema.
The table CURRENCY is created by the role DEV_PROJ_OWN, making it the table owner. As the owner, DEV_PROJ_OWN implicitly has full privileges on the table, including SELECT. Therefore, option B succeeds because the role selecting the data owns the table.
In option A, DEV_PROJ_OWN explicitly grants SELECT on the table to ANALYST_PROJ. Since this grant is performed by the schema/table owner and the role ANALYST_PROJ already has USAGE on both the database and schema, the subsequent SELECT succeeds. This makes A valid.
Option C fails because SYSADMIN does not inherit privileges from DEV_SYSADMIN or DEV_PROJ_OWN; Snowflake role inheritance is directional and not lateral. Option D fails for the same reason—MAPPING_ROLE has no privileges on the database or schema. Option E fails because ACCOUNTADMIN does not automatically bypass RBAC; without explicit USAGE and SELECT, access is denied.
Question # 31
An Architect needs to improve the performance of reports that pull data from multiple Snowflake tables, join, and then aggregate the data. Users access the reports using several dashboards. There are performance issues on Monday mornings between 9:00am-11:00am when many users check the sales reports.
The size of the group has increased from 4 to 8 users. Waiting times to refresh the dashboards has increased significantly. Currently this workload is being served by a virtual warehouse with the following parameters:
AUTO-RESUME = TRUE AUTO_SUSPEND = 60 SIZE = Medium
What is the MOST cost-effective way to increase the availability of the reports?
A.
Use materialized views and pre-calculate the data.
B.
Increase the warehouse to size Large and set auto_suspend = 600.
C.
Use a multi-cluster warehouse in maximized mode with 2 size Medium clusters.
D.
Use a multi-cluster warehouse in auto-scale mode with 1 size Medium cluster, and set min_cluster_count = 1 and max_cluster_count = 4.
Full Access
Answer:
D
Explanation:
The most cost-effective way to increase the availability and performance of the reports during peak usage times, while keeping costs under control, is to use a multi-cluster warehouse in auto-scale mode. Option D suggests using a multi-cluster warehouse with 1 size Medium cluster and allowing it to auto-scale between 1 and 4 clusters based on demand. This setup ensures that additional computing resources are available when needed (e.g., during Monday morning peaks) and are scaled down to minimize costs when the demand decreases. This approach optimizes resource utilization and cost by adjusting the compute capacity dynamically, rather than maintaining a larger fixed size or multiple clusters continuously.
[References:Snowflake's official documentation on managing warehouses and using auto-scaling features., , , , ]
Question # 32
Which of the below commands will use warehouse credits?
A.
SHOW TABLES LIKE 'SNOWFL%';
B.
SELECT MAX(FLAKE_ID) FROM SNOWFLAKE;
C.
SELECT COUNT(*) FROM SNOWFLAKE;
D.
SELECT COUNT(FLAKE_ID) FROM SNOWFLAKE GROUP BY FLAKE_ID;
Full Access
Answer:
B, C, D
Explanation:
Warehouse credits are used to pay for the processing time used by each virtual warehouse in Snowflake. A virtual warehouse is a cluster of compute resources that enables executing queries, loading data, and performing other DML operations. Warehouse credits are charged based on the number of virtual warehouses you use, how long they run, and their size1.
Among the commands listed in the question, the following ones will use warehouse credits:
SELECT MAX(FLAKE_ID) FROM SNOWFLAKE: This command will use warehouse credits because it is a query that requires a virtual warehouse to execute. The query will scan the SNOWFLAKE table and return the maximum value of the FLAKE_ID column2. Therefore, option B is correct.
SELECT COUNT(*) FROM SNOWFLAKE: This command will also use warehouse credits because it is a query that requires a virtual warehouse to execute. The query will scan the SNOWFLAKE table and return the number of rows in the table3. Therefore, option C is correct.
SELECT COUNT(FLAKE_ID) FROM SNOWFLAKE GROUP BY FLAKE_ID: This command will also use warehouse credits because it is a query that requires a virtual warehouse to execute. The query will scan the SNOWFLAKE table and return the number of rows for each distinct value of the FLAKE_ID column4. Therefore, option D is correct.
The command that will not use warehouse credits is:
SHOW TABLES LIKE ‘SNOWFL%’: This command will not use warehouse credits because it is a metadata operation that does not require a virtual warehouse to execute. The command will return the names of the tables that match the pattern ‘SNOWFL%’ in the current database and schema5. Therefore, option A is incorrect.
 Understanding Compute Cost : MAX Function : COUNT Function : GROUP BY Clause : SHOW TABLES
Question # 33
A Developer is having a performance issue with a Snowflake query. The query receives up to 10 different values for one parameter and then performs an aggregation over the majority of a fact table. It then
joins against a smaller dimension table. This parameter value is selected by the different query users when they execute it during business hours. Both the fact and dimension tables are loaded with new data in an overnight import process.
On a Small or Medium-sized virtual warehouse, the query performs slowly. Performance is acceptable on a size Large or bigger warehouse. However, there is no budget to increase costs. The Developer
needs a recommendation that does not increase compute costs to run this query.
What should the Architect recommend?
A.
Create a task that will run the 10 different variations of the query corresponding to the 10 different parameters before the users come in to work. The query results will then be cached and ready to respond quickly when the users re-issue the query.
B.
Create a task that will run the 10 different variations of the query corresponding to the 10 different parameters before the users come in to work. The task will be scheduled to align with the users' working hours in order to allow the warehouse cache to be used.
C.
Enable the search optimization service on the table. When the users execute the query, the search optimization service will automatically adjust the query execution plan based on the frequently-used parameters.
D.
Create a dedicated size Large warehouse for this particular set of queries. Create a new role that has USAGE permission on this warehouse and has the appropriate read permissions over the fact and dimension tables. Have users switch to this role and use this warehouse when they want to access this data.
Full Access
Answer:
C
Explanation:
Enabling the search optimization service on the table can improve the performance of queries that have selective filtering criteria, which seems to be the case here. This service optimizes the execution of queries by creating a persistent data structure called a search access path, which allows some micro-partitions to be skipped during the scanning process. This can significantly speed up query performance without increasing compute costs1.
References
•Snowflake Documentation on Search Optimization Service1.
Question # 34
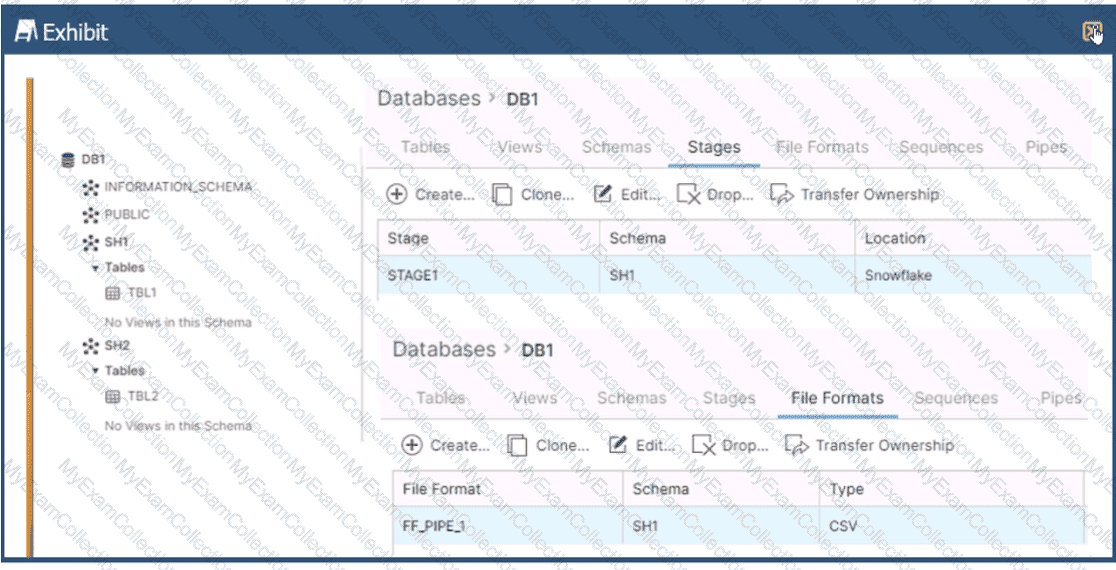
Based on the architecture in the image, how can the data from DB1 be copied into TBL2? (Select TWO).
A)

B)

C)

D)

E)

A.
Option A
B.
Option B
C.
Option C
D.
Option D
E.
Option E
Full Access
Answer:
B, E
Explanation:
The architecture in the image shows a Snowflake data platform with two databases, DB1 and DB2, and two schemas, SH1 and SH2. DB1 contains a table TBL1 and a stage STAGE1. DB2 contains a table TBL2. The image also shows a snippet of code written in SQL language that copies data from STAGE1 to TBL2 using a file format FF PIPE 1.
To copy data from DB1 to TBL2, there are two possible options among the choices given:
Option B: Use a named external stage that references STAGE1. This option requires creating an external stage object in DB2.SH2 that points to the same location as STAGE1 in DB1.SH1. The external stage can be created using the CREATE STAGE command with the URL parameter specifying the location of STAGE11. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
use database DB2;
use schema SH2;
createstage EXT_STAGE1
url=@DB1.SH1.STAGE1;
Then, the data can be copied from the external stage to TBL2 using the COPY INTO command with the FROM parameter specifying the external stage name and the FILE FORMAT parameter specifying the file format name2. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
copyintoTBL2
from@EXT_STAGE1
file format=(format name=DB1.SH1.FF PIPE1);
Option E: Use a cross-database query to select data from TBL1 and insert into TBL2. This option requires using the INSERT INTO command with the SELECT clause to query data from TBL1 in DB1.SH1 and insert it into TBL2 in DB2.SH2. The query must use the fully-qualified names of the tables, including the database and schema names3. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
use database DB2;
use schema SH2;
insertintoTBL2
select*fromDB1.SH1.TBL1;
The other options are not valid because:
Option A: It uses an invalid syntax for the COPY INTO command. The FROM parameter cannot specify a table name, only a stage name or a file location2.
Option C: It uses an invalid syntax for the COPY INTO command. The FILE FORMAT parameter cannot specify a stage name, only a file format name or options2.
Option D: It uses an invalid syntax for the CREATE STAGE command. The URL parameter cannot specify a table name, only a file location1.
1: CREATE STAGE | Snowflake Documentation
2: COPY INTO table | Snowflake Documentation
3: Cross-database Queries | Snowflake Documentation
Question # 35
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously ang efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
A.
Ingest the data using COPY INTO and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
B.
Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Create an external function to do model inference with Amazon Comprehend and write the final records to a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
C.
Ingest the data into Snowflake using Amazon EMR and PySpark using the Snowflake Spark connector. Apply transformations using another Spark job. Develop a python program to do model inference by leveraging the Amazon Comprehend text analysis API. Then write the results to a Snowflake table and create a listing in the Snowflake Marketplace to make the data available to other companies.
D.
Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
Full Access
Answer:
B
Explanation:
This design meets all the requirements for the data pipeline. Snowpipe is a feature that enables continuous data loading into Snowflake from object storage using event notifications. It is efficient, scalable, and serverless, meaning it does not require any infrastructure or maintenance from the user. Streams and tasks are features that enable automated data pipelines within Snowflake, using change data capture and scheduled execution. They are also efficient, scalable, and serverless, and they simplify the data transformation process. External functions are functions that can invoke external services or APIs from within Snowflake. They can be used to integrate with Amazon Comprehend and perform sentiment analysis on the data. The results can be written back to a Snowflake table using standard SQL commands. Snowflake Marketplace is a platform that allows data providers to share data with data consumers across different accounts, regions, and cloud platforms. It is a secure and easy way to make data publicly available to other companies.
Snowpipe Overview | Snowflake Documentation
Introduction to Data Pipelines | Snowflake Documentation
External Functions Overview | Snowflake Documentation
Snowflake Data Marketplace Overview | Snowflake Documentation
Question # 36
Files arrive in an external stage every 10 seconds from a proprietary system. The files range in size from 500 K to 3 MB. The data must be accessible by dashboards as soon as it arrives.
How can a Snowflake Architect meet this requirement with the LEAST amount of coding? (Choose two.)
A.
Use Snowpipe with auto-ingest.
B.
Use a COPY command with a task.
C.
Use a materialized view on an external table.
D.
Use the COPY INTO command.
E.
Use a combination of a task and a stream.
Full Access
Answer:
A, E
Explanation:
The requirement is for the data to be accessible as quickly as possible after it arrives in the external stage with minimal coding effort.
Option A:Snowpipe with auto-ingest is a service that continuously loads data as it arrives in the stage. With auto-ingest, Snowpipe automatically detects new files as they arrive in a cloud stage and loads the data into the specified Snowflake table with minimal delay and no intervention required. This is an ideal low-maintenance solution for the given scenario where files are arriving at a very high frequency.
Option E:Using a combination of a task and a stream allows for real-time change data capture in Snowflake. A stream records changes (inserts, updates, and deletes) made to a table, and a task can be scheduled to trigger on a very short interval, ensuring that changes are processed into the dashboard tables as they occur.
Question # 37
A user has activated primary and secondary roles for a session.
What operation is the user prohibited from using as part of SQL actions in Snowflake using the secondary role?
A.
Insert
B.
Create
C.
Delete
D.
Truncate
Full Access
Answer:
B
Explanation:
In Snowflake, when a user activates a secondary role during a session, certain privileges associated with DDL (Data Definition Language) operations are restricted. TheCREATEstatement, which falls under DDL operations, cannot be executed using a secondary role. This limitation is designed to enforce role-based access control and ensure that schema modifications are managed carefully, typically reserved for primary roles that have explicit permissions to modify database structures.
[References:Snowflake's security and access control documentation specifying the limitations and capabilities of primary versus secondary roles in session management., , , , ]
Question # 38
A user, analyst_user has been granted the analyst_role, and is deploying a SnowSQL script to run as a background service to extract data from Snowflake.
What steps should be taken to allow the IP addresses to be accessed? (Select TWO).
A.
ALTERROLEANALYST_ROLESETNETWORK_POLICY='ANALYST_POLICY';
B.
ALTERUSERANALYSTJJSERSETNETWORK_POLICY='ANALYST_POLICY';
C.
ALTERUSERANALYST_USERSETNETWORK_POLICY='10.1.1.20';
D.
USE ROLE SECURITYADMIN;CREATE OR REPLACE NETWORK POLICY ANALYST_POLICY ALLOWED_IP_LIST = ('10.1.1.20');
E.
USE ROLE USERADMIN;CREATE OR REPLACE NETWORK POLICY ANALYST_POLICYALLOWED_IP_LIST = ('10.1.1.20');
Full Access
Answer:
B, D
Explanation:
To ensure that ananalyst_usercan only access Snowflake from specific IP addresses, the following steps are required:
Option B: This alters the network policy directly linked toanalyst_user. Setting a network policy on the user level is effective and ensures that the specified network restrictions apply directly and exclusively to this user.
Option D: Before a network policy can be set or altered, the appropriate role with permission to manage network policies must be used.SECURITYADMINis typically the role that has privileges to create and manage network policies in Snowflake. Creating a network policy that specifies allowed IP addresses ensures that only requests coming from those IPs can access Snowflake under this policy. After creation, this policy can be linked to specific users or roles as needed.
Options A and E mention altering roles or using the wrong role (USERADMINtypically does not manage network security settings), and option C incorrectly attempts to set a network policy directly as an IP address, which is not syntactically or functionally valid.
[References:Snowflake's security management documentation covering network policies and role-based access controls., , , , , ]
Question # 39
An Architect executes the following statements in order:
CREATE TABLE emp (id INTEGER);
INSERT INTO emp VALUES (1),(2);
CREATE TEMPORARY TABLE emp (id INTEGER);
INSERT INTO emp VALUES (1);
Then executes:
SELECT COUNT(*) FROM emp;
DROP TABLE emp;
SELECT COUNT(*) FROM emp;
What will be the result?
A.
COUNT() = 2
COUNT() = 1
B.
COUNT() = 1
COUNT() = 2
C.
COUNT() = 2
COUNT() = 2
D.
The final query results in an error.
Full Access
Answer:
B
Explanation:
In Snowflake, temporary tables take precedence over permanent tables when they share the same name and exist in the same session. After creating the permanent emp table and inserting two rows, a temporary table with the same name is created. From that point forward in the session, all references to emp resolve to the temporary table, not the permanent one.
The insert following the creation of the temporary table adds one row to the temporary table. Therefore, the first SELECT COUNT(*) FROM emp returns 1, reflecting the single row in the temporary table.
When DROP TABLE emp is executed, it drops the temporary table first because it shadows the permanent table. After the temporary table is dropped, the permanent table named emp becomes visible again within the session. The final SELECT COUNT(*) FROM emp then queries the permanent table, which still contains the original two rows inserted earlier.
This behavior is frequently tested in SnowPro Architect exams to validate understanding of object resolution precedence, session scope, and temporary object behavior.
=========
Question # 40
A retailer's enterprise data organization is exploring the use of Data Vault 2.0 to model its data lake solution. A Snowflake Architect has been asked to provide recommendations for using Data Vault 2.0 on Snowflake.
What should the Architect tell the data organization? (Select TWO).
A.
Change data capture can be performed using the Data Vault 2.0 HASH_DIFF concept.
B.
Change data capture can be performed using the Data Vault 2.0 HASH_DELTA concept.
C.
Using the multi-table insert feature in Snowflake, multiple Point-in-Time (PIT) tables can be loaded in parallel from a single join query from the data vault.
D.
Using the multi-table insert feature, multiple Point-in-Time (PIT) tables can be loaded sequentially from a single join query from the data vault.
E.
There are performance challenges when using Snowflake to load multiple Point-in-Time (PIT) tables in parallel from a single join query from the data vault.
Full Access
Answer:
A, C
Explanation:
Data Vault 2.0 on Snowflake supports the HASH_DIFF concept for change data capture, which is a method to detect changes in the data by comparing the hash values of the records. Additionally, Snowflake’s multi-table insert feature allows for the loading of multiple PIT tables in parallel from a single join query, which can significantly streamline the data loading process and improve performance1.
References =
•Snowflake’s documentation on multi-table inserts1
•Blog post on optimizing Data Vault architecture on Snowflake2
Question # 41
A new user user_01 is created within Snowflake. The following two commands are executed:
Command 1→ SHOW GRANTS TO USER user_01;
Command 2→ SHOW GRANTS ON USER user_01;
What inferences can be made about these commands?
A.
Command 1 defines which user owns user_01Command 2 defines all the grants which have been given to user_01
B.
Command 1 defines all the grants which are given to user_01Command 2 defines which user owns user_01
C.
Command 1 defines which role owns user_01Command 2 defines all the grants which have been given to user_01
D.
Command 1 defines all the grants which are given to user_01Command 2 defines which role owns user_01
Full Access
Answer:
D
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
To understand this, we must differentiate between:
SHOW GRANTS TO
SHOW GRANTS ON
1. SHOW GRANTS TO USER user_01;
This commandlists all the privileges granted to the useruser_01. These can include:
Roles granted to the user
Global privileges such as MONITOR, USAGE, etc.
🔹Official Documentation Extract:
"SHOW GRANTS TO USERdisplays the roles and other privileges that have been granted to the specified user."
Source: Snowflake Docs – SHOW GRANTS TO
Question # 42
An Architect needs to automate the daily Import of two files from an external stage into Snowflake. One file has Parquet-formatted data, the other has CSV-formatted data.
How should the data be joined and aggregated to produce a final result set?
A.
Use Snowpipe to ingest the two files, then create a materialized view to produce the final result set.
B.
Create a task using Snowflake scripting that will import the files, and then call a User-Defined Function (UDF) to produce the final result set.
C.
Create a JavaScript stored procedure to read. join, and aggregate the data directly from the external stage, and then store the results in a table.
D.
Create a materialized view to read, Join, and aggregate the data directly from the external stage, and use the view to produce the final result set
Full Access
Answer:
B
Explanation:
According to the Snowflake documentation, tasks are objects that enable scheduling and execution of SQL statements or JavaScript user-defined functions (UDFs) in Snowflake. Tasks can be used to automate data loading, transformation, and maintenance operations. Snowflake scripting is a feature that allows writing procedural logic using SQL statements and JavaScript UDFs. Snowflake scripting can be used to create complex workflows and orchestrate tasks. Therefore, the best option to automate the daily import of two files from an external stage into Snowflake, join and aggregate the data, and produce a final result set is to create a task using Snowflake scripting that will import the files using the COPY INTO command, and then call a UDF to perform the join and aggregation logic. The UDF can return a table or a variant value as the final result set. References:
Tasks
Snowflake Scripting
User-Defined Functions
Question # 43
An Architect is designing a solution that will be used to process changed records in an orders table. Newly-inserted orders must be loaded into the f_orders fact table, which will aggregate all the orders by multiple dimensions (time, region, channel, etc.). Existing orders can be updated by the sales department within 30 days after the order creation. In case of an order update, the solution must perform two actions:
1. Update the order in the f_0RDERS fact table.
2. Load the changed order data into the special table ORDER _REPAIRS.
This table is used by the Accounting department once a month. If the order has been changed, the Accounting team needs to know the latest details and perform the necessary actions based on the data in the order_repairs table.
What data processing logic design will be the MOST performant?
A.
Useone stream and one task.
B.
Useone stream and two tasks.
C.
Usetwo streams and one task.
D.
Usetwo streams and two tasks.
Full Access
Answer:
B
Explanation:
The most performant design for processing changed records, considering the need to both update records in thef_ordersfact table and load changes into theorder_repairstable, is to use one stream and two tasks. The stream will monitor changes in the orders table, capturing both inserts and updates. The first task would apply these changes to thef_ordersfact table, ensuring all dimensions are accurately represented. The second task would use the same stream to insert relevant changes into theorder_repairstable, which is critical for the Accounting department's monthly review. This method ensures efficient processing by minimizing the overhead of managing multiple streams and synchronizing between them, while also allowing specific tasks to optimize for their target operations.
[References:Snowflake's documentation on streams and tasks for handling data changes efficiently., , , , ]
Question # 44
A company is storing large numbers of small JSON files (ranging from 1-4 bytes) that are received from IoT devices and sent to a cloud provider. In any given hour, 100,000 files are added to the cloud provider.
What is the MOST cost-effective way to bring this data into a Snowflake table?
A.
An external table
B.
A pipe
C.
A stream
D.
A copy command at regular intervals
Full Access
Answer:
B
Explanation:
A pipe is a Snowflake object that continuously loads data from files in a stage (internal or external) into a table. A pipe can be configured to use auto-ingest, which means that Snowflake automatically detects new or modified files in the stage and loads them into the table without any manual intervention1.
A pipe is the most cost-effective way to bring large numbers of small JSON files into a Snowflake table, because it minimizes the number of COPY commands executed and the number of micro-partitions created. A pipe can use file aggregation, which means that it can combine multiple small files into a single larger file before loading them into the table. This reduces the load time and the storage cost of the data2.
An external table is a Snowflake object that references data files stored in an external location, such as Amazon S3, Google Cloud Storage, or Microsoft Azure Blob Storage. An external table does not store the data in Snowflake, but only provides a view of the data for querying. An external table is not a cost-effective way to bring data into a Snowflake table, because it does not support file aggregation, and it requires additional network bandwidth and compute resources to query the external data3.
A stream is a Snowflake object that records the history of changes (inserts, updates, and deletes) made to a table. A stream can be used to consume the changes from a table and apply them to another table or a task. A stream is not a way to bring data into a Snowflake table, but a way to process the data after it is loaded into a table4.
A copy command is a Snowflake command that loads data from files in a stage into a table. A copy command can be executed manually or scheduled using a task. A copy command is not a cost-effective way to bring large numbers of small JSON files into a Snowflake table, because it does not support file aggregation, and it may create many micro-partitions that increase the storage cost of the data5.
 Pipes : Loading Data Using Snowpipe : External Tables : Streams : COPY INTO



