Question # 4
During a system boot cycle, what program is executed after the BIOS completes its tasks?
Question # 5
Which of the following are init systems used within Linux systems? (Choose THREE correct answers.)
Question # 6
The USB device filesystem can be found under /proc/______/usb/. (Please fill in the blank with the single word only)

Question # 7
Which of the following kernel parameters instructs the kernel to suppress most boot messages?
Question # 8
The message "Hard Disk Error" is displayed on the screen during Stage 1 of the GRUB boot process. What does this indicate?
Question # 9
Which command displays the contents of the Kernel Ring Buffer on the command line? (Provide only the command name without any options or path information)
Question # 10
Which of the following commands reboots the system when using SysV init? (Choose TWO correct answers.)
Question # 11
What information can the lspci command display about the system hardware? (Choose THREE correct answers.)
Question # 12
During a system boot cycle, what is the program that is run after the BIOS completes its tasks?
Question # 13
Which command will display messages from the kernel that were output during the normal boot sequence?
Question # 14
You suspect that a new ethernet card might be conflicting with another device. Which file should you check within the /proc tree to learn which IRQs are being used by which kernel drivers?

Question # 15
You are having some trouble with a disk partition and you need to do maintenance on this partition but your users home directories are on it and several are logged in. Which command would disconnect the users and allow you to safely execute maintenance tasks?
Question # 18
Which command creates a swap space on a block device or a file? (Specify ONLY the command without any path or parameters.)
Question # 19
Which option to the tee command will cause the output to be concatenated on the end of the output file instead of overwriting the existing file contents?
Question # 20
What do the permissions -rwSr-xr-x mean for a binary file when it is executed as a command?
Question # 21
Which of the following commands changes all occurrences of the word “bob†in file data to “Bob†and prints the result to standard output?
Question # 22
Which of the following commands shows the definition of a given shell command?
Question # 23
In compliance with the FHS, in which of the following directories are documentation files found?
Question # 24
Which of the following commands instructs SysVinit to reload its configuration file?
Question # 25
Which of the following commands set the sticky bit for the directory /tmp? (Choose TWO correct answers.)
Question # 26
Which command will uninstall a package but leave its configuration files in case the package is re-installed?
Question # 27
Which of the following pieces of information of an existing file is changed when a hard link pointing to that file is created?
Question # 29
When piping the output of find to the xargs command, what option to find is useful if the filenames have spaces in them?
Question # 31
The system configuration file named _______ is commonly used to set the default runlevel. (Please provide the file name with full path information)
Question # 32
After running the command umount /mnt, the following error message is displayed:
umount: /mnt: device is busy.
What is a common reason for this message?
Question # 34
Creating a hard link to an ordinary file returns an error. What could be the reason for this?
Question # 35
Which of the following commands moves and resumes in the background the last stopped shell job?
Question # 36
While editing a file in vi, the file changes due to another process. Without exiting vi, how can the file be reopened for editing with the new content?
Question # 37
What is the maximum niceness value that a regular user can assign to a process with the nice command when executing a new process?
Question # 38
When given the following command line.
echo "foo bar" | tee bar | cat
Which of the following output is created?
Question # 39
What happens after issuing the command vi without any additional parameters?
Question # 40
Which of the following commands can be used to create a USB storage media from a disk image?
Question # 41
Which of the following characters can be combined with a separator string in order to read from the current input source until the separator string, which is on a separate line and without any trailing spaces, is reached?
Question # 42
Which character, added to the end of a command, runs that command in the background as a child process of the current shell?
Question # 43
Which of the following commands prints a list of usernames (first column) and their primary group (fourth column) from the /etc/passwd file?
Question # 44
Which of the following explanations are valid reasons to run a command in the background of your shell?
Question # 45
Which variable defines the directories in which a Bash shell searches for executable commands?
Question # 46
Which of the following commands will print the last 10 lines of a text file to the standard output?
Question # 48
Which of the following commands will reduce all consecutive spaces down to a single space?
Question # 49
A user accidentally created the subdirectory \dir in his home directory. Which of the following commands will remove that directory?
Question # 50
Which of the following commands kills the process with the PID 123 but allows the process to "clean up" before exiting?
Question # 51
Which command displays the current disk space usage for all mounted file systems? (Specify ONLY the command without any path or parameters.)
Question # 52
Which program runs a command in specific intervals and refreshes the display of the program’s output? (Specify ONLY the command without any path or parameters.)
Question # 53
If an alias Is exists, which of the following commands updates the ai as to point to dig contmfl nd is -1 instead of the alias's current target?
Question # 54
What is the first program the Linux kernel starts at boot time when using System V init?
Question # 55
Which of the following shell redirections will write standard output and standard error output to a file named filename?
Question # 60
Which of the following commands lists the dependencies of the RPM package file foo.rpm?
Question # 61
Consider the following directory:
drwxrwxr-x 2 root sales 4096 Jan 1 15:21 sales
Which command ensures new files created within the directory sales are owned by the group sales? (Choose two.)
Question # 62
Which of the following commands list all files and directories within the /tmp/ directory and its subdirectories which are owned by the user root? (Choose two.)
Question # 63
Which of the following commands finds all files owned by root that have the SetUID bit set?
Question # 64
Which of the following regular expressions represents a single upper-case letter?
Question # 65
When considering the use of hard links, what are valid reasons not to use hard links?
Question # 66
Given a log file loga.log with timestamps of the format DD/MM/YYYY:hh:mm:ss, which command filters out all log entries in the time period between 8:00 am and 8:59 am?
Question # 67
Which of the following commands display the number of bytes transmitted and received via the eth0 network interfaced (Choose TWO correct answers.)
Question # 68
Consider the following output from the command ls –i:
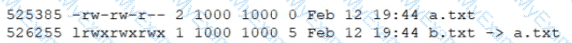
How would a new file named c.txt be created with the same inode number as a.txt (Inode 525385)?
Question # 69
Which of the following apt-get commands will install the newest versions of all currently installed packages without removing any packages or installing new packages that are not already installed?
Question # 70
If neither cron. allow nor cron. deny exist in /etc/, which of the following is true?
Question # 71
Which Debian package management tool asks the configuration questions for a specific already installed package just as if the package were being installed for the first time? (Specify ONLY the command without any path or parameters.)
Question # 72
Which of the following commands lists the dependencies of a given dpkg package?
Question # 73
Which of the following commands lists all currently installed packages when using RPM package management?
Question # 74
After modifying GNU GRUB's configuration file, which command must be run for the changes to take effect?
Question # 75
When using rpm --verify to check files created during the installation of RPM packages, which of the following information is taken into consideration? (Choose THREE correct answers.)
Question # 76
Which of the following commands is used to update the list of available packages when using dpkg based package management?
Question # 77
What is the difference between the --remove and the --purge action with the dpkg command?
Question # 78
Which option to the yum command will update the entire system? (Specify ONLY the option name without any additional parameters.)
update
upgrade
Question # 79
The dpkg-____ command will ask configuration questions for a specified package, just as if the package were being installed for the first time.
Question # 80
Which of the following commands overwrites the bootloader located on /dev/sda without overwriting the partition table or any data following it?
Question # 81
When removing a package, which of the following dpkg options will completely remove the files including configuration files?
Question # 82
In which directory must definition files be placed to add additional repositories to yum?
/etc/yum.repos.d
/etc/yum.repos.d/
yum.repos.d
yum.repos.d/
Question # 83
Which world-writable directory should be placed on a separate partition in order to prevent users from being able to fill up the / filesystem? (Specify the full path to the directory.)

Question # 84
What can the Logical Volume Manager (LVM) be used for? (Choose THREE correct answers.)
Question # 85
You want to preview where the package file, apache-xml.i386.rpm, will install its files before installing it. What command do you issue?
Question # 86
An administrator has issued the following command:
grub-install --root-directory=/custom-grub /dev/sda
In which directory will new configuration files be found? (Provide the full directory path only without the filename)
Question # 87
Typically, which top level system directory is used for files and data that change regularly while the system is running and are to be kept between reboots? (Specify only the top level directory)

